“Suutarin lapsella on kengät” – Netvisor-integraatio
“Suutarin lapsella on kengät” – Netvisor-integraatio
Olin tässä taannoin asiakkaan luona konsultoimassa Azure Data Platformin mahdollisuuksista ja hyvin menneen session päätteeksi joku asiakkaista kysäisi pilke silmäkulmassa “Mites teidän omat tiedonhallintaratkaisut? Onko meihin liittyvät projektidatat tallessa ja turvassa? Onkos suutarin lapsella kenkiä?”. Ja tähän pienen alkuhämmennyksen jälkeen vastasin “Toki! Mekin käytämme Azure Data Platformia ja sen palveluita”. Ja tämä on totta. Suutarin lapsella on sittenkin kengät! Ja miksipä en kertoisi tarkemmin miten me käytämme Azure-ratkaisuja ja mikä meidän suunnitelma on niiden osalta tulevaisuudessa. Tässä ensimmäisessä osassa käyn läpi yleisarkkitehtuurin ja avaan Netvisor-integraatiota, jonka kautta saamme ajantasaista tietoa kassavirta- ja talousraportointiin.
Azure Data Platform -arkkitehtuuri
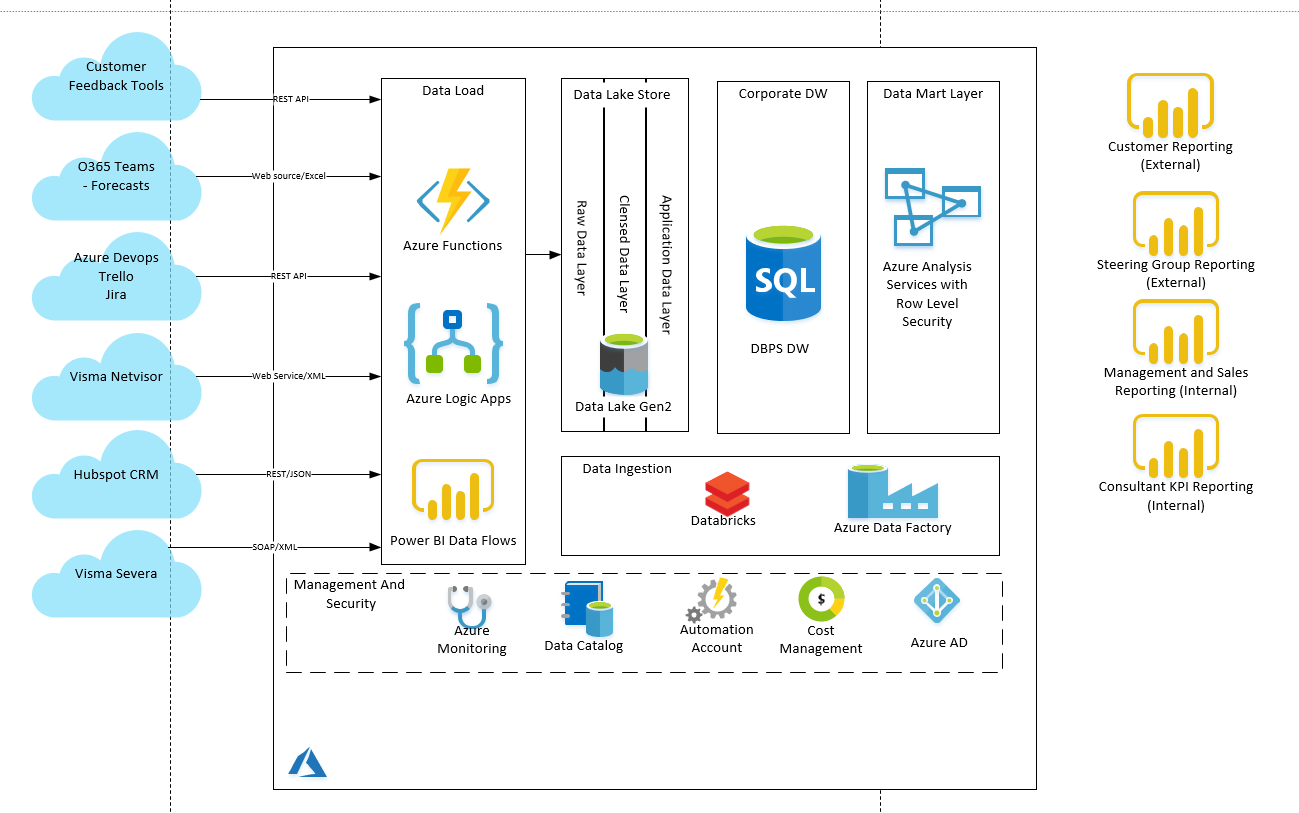
Arkkitehtuurikuva (kuva 1.) kertoo pääpirteissään mistä on kysymys. Ratkaisumme koostuu useasta eri Azure-palvelusta, joita sitten hallinnoidaan Azure Data Factoryn kautta. Tiedon lataamiseen data lähteistä käytössä on Azure Logic Appsia ja Power BI Data Flowta. Tiedot tallennetaan Azure Data Lakeen (Blob storage ja Data Lake Gen2), jossa niitä käsitellään ja täydennetään Azure Databricksin scripteillä. Valmis data viedään storagesta Azure SQL:ään ja edelleen Azure Analysis Services -kuutioon. Kuution ja dynaamisen securityn käyttö tosin odottaa asiakasraportoinnin valmistumista ja toistaiseksi raportoimme Power BI:llä suoraan Azure SQL:stä.
Integraatio-ratkaisuista Azure Logic Apps on erinomainen työkalu kun dataa haetaan API-rajapinnoista. API-rajapintojen tyypilliset hakurajoitukset kuten sivutukset, on helppo toteuttaa Logic Appsin iteraatiotoiminnoilla. Lisäksi Logic Appsin toimintaa voidaan helposti laajentaa Azure Functionien kautta. Power BI Dataflows on taas täysin ilmainen (jos Power BI -lisenssit on kunnossa) ja valmiit datasetit pystytään tallentamaan Data Lake Gen2:seen. Tosin tässä on 10GB rajoitus per käyttäjä (Premium-lisenssillä 100GB), joka meille riittää hyvin.
Netvisor -integraatio
Olemme toteuttaneet integraatiot meillä käytössä oleviin Visma Severaan (toiminnanohjausjärjestelmä), Visma Netvisoriin (taloushallinto ja laskutus), Hubspot CRM sekä muutamiin muihin meille keskeisiin työkaluihin. Käyn tässä blogissa läpi Netvisor-integraation toteutuksen pääpiirteissään. Netvisor-integraation tavoitteena on hakea datat liittyen tulos- ja taseraportointiin sekä kassavirtalaskelmaan. Nykyiset Netvisorin tarjoamat omat raportit eivät riitä vaan tarve olisi pysytä porautumaan raportilla aina tositeriville asti. Ensimmäisessä vaiheessa pärjäämme GeneralLedger- ja AccountList- tiedoilla.
Azure Logic Apps ja Azure Function
Netvisorin API -rajapinnan käyttö vaatii ns. MAC-koodin laskemisen lähtöparametrien perusteella. Tästä syystä Azure Logic Appsilla toteutettuun ratkaisuun on lisätty Azure Function -kutsuja MAC-koodin laskemista varten. Azure Function-sovellus on c#-koodia ja sen rajapinta on http post -kutsu. Azure Functionin palauttamaa mac-koodia käytetään kussakin Netvisor-rajapintahaussa yhtenä parametrinä. Rajapinta palauttaa hakutulokset XML-formaatissa ja ne tallennetaan sellaisenaan Azure Blob Storageen.
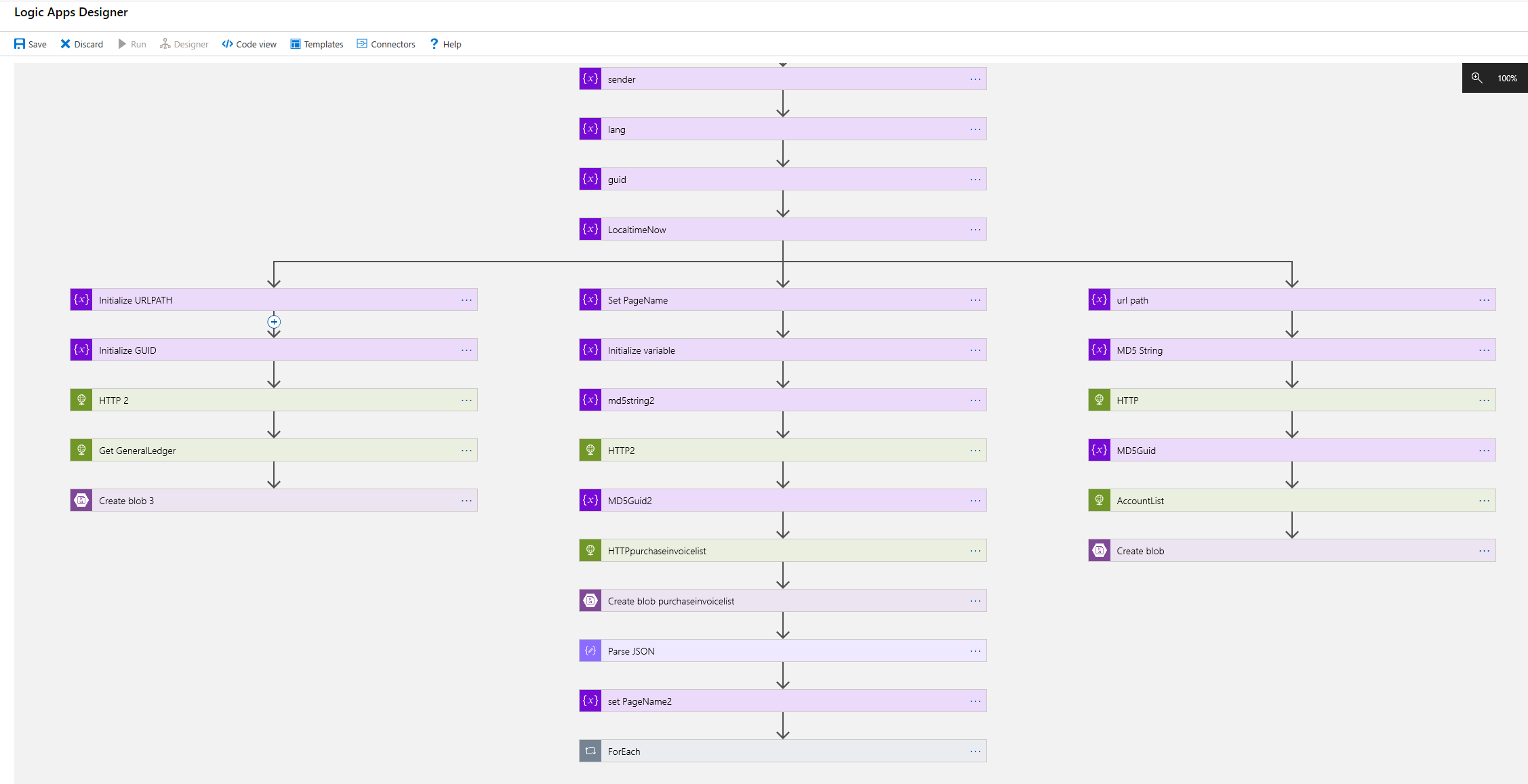
Tutkin pitkään, miten XML:n saisi jo Logic Apps-sovelluksessa muutettua geneerisemmäksi JSON:ksi, mutta päädyin ratkaisuun, jossa muunnos tehdään Azure Databricksin kautta. Logic Appsissa on mahdollista tehdä muunnos käyttäen funktiokutsua json(xml(<content>)), mutta huomasin että tässä on bugi, eikä listatyyppisen datan konversio tuottanut oikeaa json-formaattia. Toinen vaihtoehto on käyttää Transform XML tai Liquid -toiminnallisuuksia, mutta ne vaativat Azure Integration Accountin käyttöottoa ja sen kustannus on aivan liian kallis tässä kohtaa (lue useita satoja euroja per kk).
Azure Databricks – xml:stä jsoniin
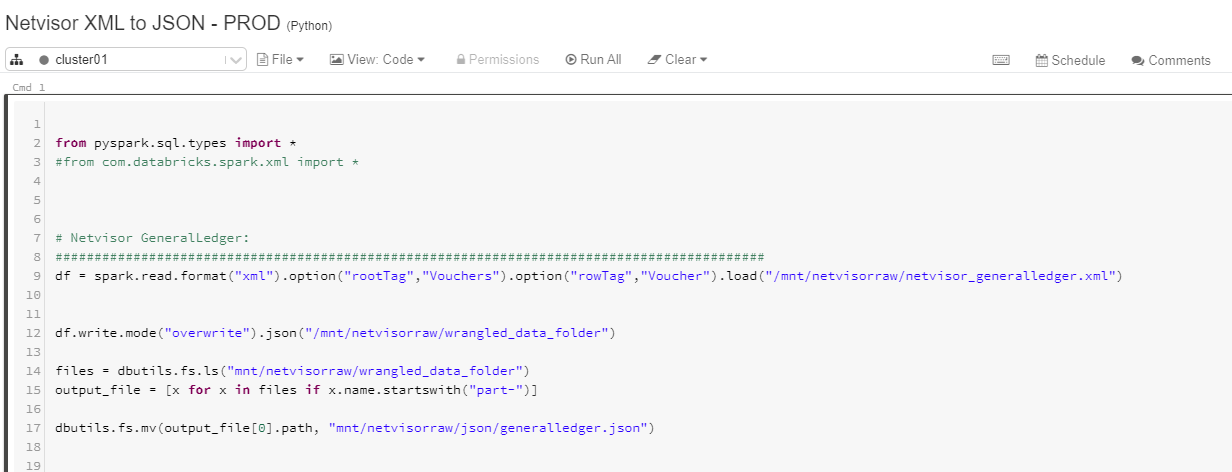
Databricksiä käytetään Netvisor-integraatiossa pelkästään XML:n muuttamisessa JSON-formaattiin. XML luetaan ensin dataframeen josta se kirjoitetaan json-formaatissa takaisin blob storageen. Azure Databricks workspaceen pitää tuoda spark-xml -parseri joka löytyy Maven-repositorystä ja sen tarkempi dokumentaatio githubista löytyy täältä https://github.com/databricks/spark-xml . Kuvassa 3. näkyy myös Pythonkoodi millä tiedosto saadaan nimettyä halutun nimiseksi (tässä tapauksessa generalledger.json).
UTF-16 -konversio
Tässä kohtaa luulin, että data on valmiina ladattavaksi Azure SQL-kantaan suoraan Azure Blob-storagesta, mutta eteen tulikin merkistöongelma. Yllättäen ääkköset eli skandit eivät näkyneet oikein. UTF8-formaatti pitää saada muutettua UTF 16-formaattiin ja tähän löytyikin helppo ratkaisu Azure Data Factoryn kautta. Tehdään Copy-activity, jossa sink-datasetin encoding -arvo asetetaan UTF-16. Samalla kopioidaan tiedosto Azure Blob -storagessa stage-alueelle.

Azure SQL ja external table
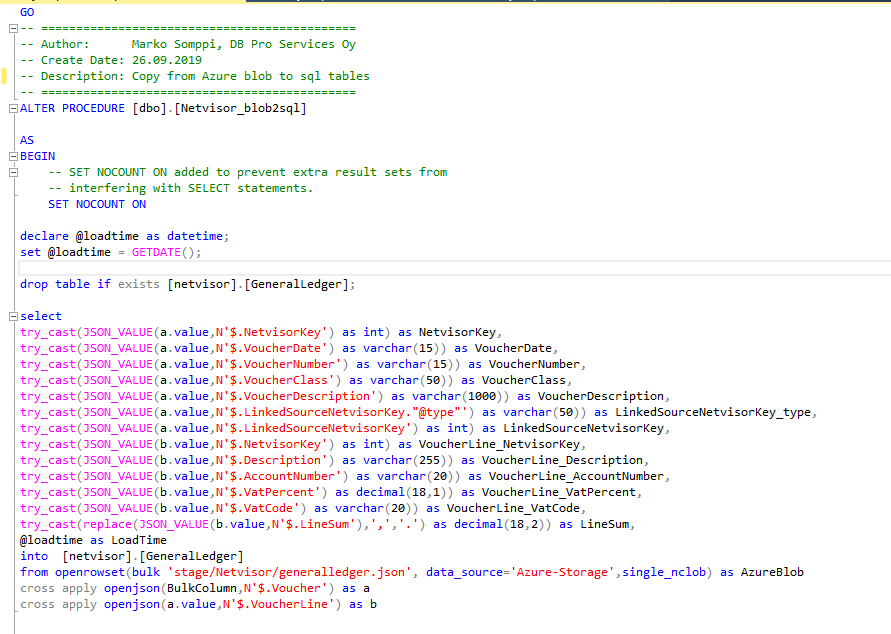
Seuraava vaihe on saada data Azure SQL:ään. Otimme muuten käyttöön Azure SQL:n serverless-version (https://docs.microsoft.com/en-us/azure/sql-database/sql-database-serverless ), jolloin ei tarvitse maksaa kannan ”staattisesta” käytöstä. Tietokannan kustannus on merkittävästi edullisempi näin. Kuvan 5. sql -stored proseduurilla data luetaan ja parsitaan suoraan Azure Storagesta external-data sourcen kautta sql-tauluun. Huomaa että openrowset:ssa pitää käyttää single_nclob, jotta UTF-16 formaatissa oleva data saadaan luettua oikein skandien kera.
Latausten hallinta – Azure Data Factory
Lopuksi kun palaset on saatu kohdilleen, niin luodaan Azure Data Factory Pipelinet ajojen hallintaan. Tarvitaan kaksi pipelinea:
- 01_Logic Apps -pipeline. Käynnistää Netvisor-intgraation Logic Apps -toteuksen web-rajapinnan kautta.
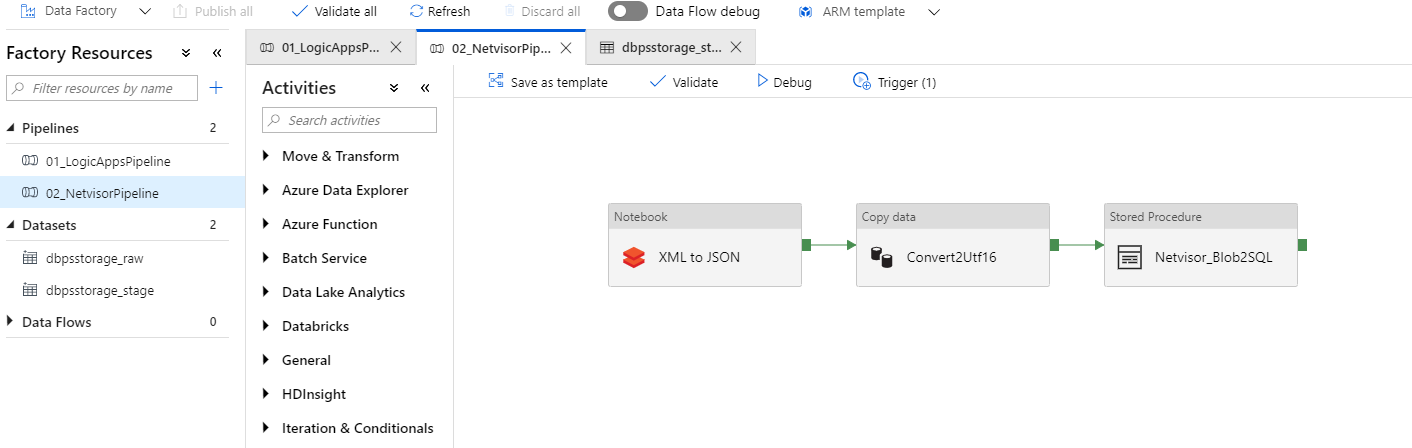
- 02_Netvisor-pipeline. Käynnistää ensin Databricks -notebookin ja klusterin (klusteri sammuu automaattisesti 10min kuluttua). Seuraava steppi on tehdä UTF-16 konversio ja lopuksi kutsuu Azure SQL:n stored prosedurea.
Näitä ajoketjuja ei voi yhdistää samaan koska ensimmäinen käynnistetään web-rajapinnan kautta eikä pipeline tiedä koska Logic apps -työ on tehty loppuun (näyttää valmista jo 1-2 sekunnin kuluttua). Tässä kohtaa tämä ei kuitenkaan ole iso ongelma. Ajot kestävät vain muutaman minuutin ja ne on helppo ajastaan niin että ensimmäinen on varmasti valmis ennen kuin toinen lähtee liikkeelle.
Power BI -raportti
Kun data on saatu Azure SQL -kantaan siitä onkin helppo toteuttaa meidän Power BI Talousraportointi -pohjalla porautuva tulos- ja taseraportti. Mutta siitä tarkemmin seuraavassa blogissa 😉 .
Kaipaatko tukea Azure Data Platform ratkaisujen käyttöönotossa tai hyödyntämisessä? Ota yhteyttä ja keskustellaan, kuinka voimme auttaa!
DB Pro Services
Marko Somppi, CEO, Partner


