Ota käyttöösi nykyaikaiset tiedolla johtamisen työkalut Microsoft Fabric:n avulla
Fragmentoitunut ja reaktiivinen dataratkaisujen kehittäminen on ajanut yrityksiä tilanteeseen, jossa data- ja analytiikkaympäristöt ovat kasvaneet vuosien [...]


Fragmentoitunut ja reaktiivinen dataratkaisujen kehittäminen on ajanut yrityksiä tilanteeseen, jossa data- ja analytiikkaympäristöt ovat kasvaneet vuosien [...]

Prosessi Datan visualisoinnissa oikean visualisointityypin valinta on kriittinen osa raportointia ja data-analytiikkaa. Käsittelen tässä blogissa prosessia [...]

Saatat ehkä pohtia, mitä konkreettisia hyötyjä yrityksellesi tulisi, mikäli korvaisit traditionaalisen operatiivisen raportoinnin tietovarastoratkaisulla (Enterprise Data [...]

Puhuttaessa modernista tietovarastoinnista ja sen arkkitehtuureista ei voi olla törmäämättä erilaisten tietojärvien ja tietovarastojen käsitteisiin. Tässä [...]

Johdanto Tietoon perustuva päätöksenteko on nykypäivän liiketoiminnassa yhä tärkeämpää. Se auttaa yrityksiä tekemään parempia päätöksiä, optimoimaan [...]
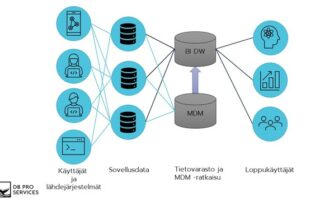
Tietoalustojen ja pilviteknologioiden kehityksen myötä yritykset panostavat tietoon perustuvaan päätöksentekoon. Tietoa käsitellään ja säilötään kasvavissa määrin [...]
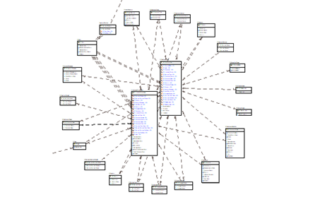
Kun organisaatio käynnistelee tiedolla johtamista, datan varastoksi käsitetään usein operatiiviset järjestelmät. Jos kuitenkin tarkastelemme tällaisen operatiivisen tietovaraston (OLTP), kuten esimerkiksi [...]

Power BI Dataflows – enemmän aikaa tiedon analysointiin Power BI on mitä mainioin itsepalvelu-BI-työkalu. Se sisältää [...]