Raporteista keskusteluun: Miten AI-agentit ja MCP-arkkitehtuuri uudistavat BI:n
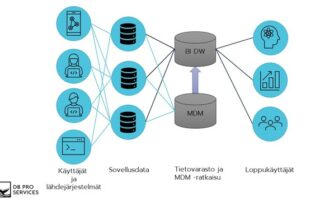
Business Intelligencen perusta: mallinnettu ja visualisoitu tieto Business Intelligence rakentuu mallinnetun ja visualisoidun tiedon varaan. Data tuodaan eri lähdejärjestelmistä, tarkistetaan ja yhtenäistetään yhteiseen rakenteeseen. Tämän jälkeen rakennetaan semanttinen malli, jossa määritellään mittarit, relaatiot ja [...]