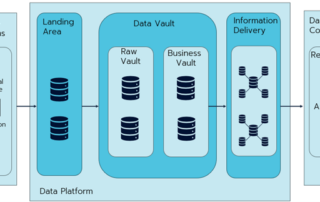
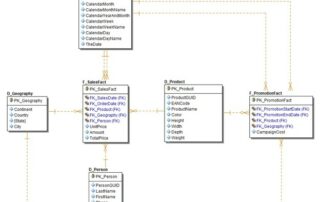
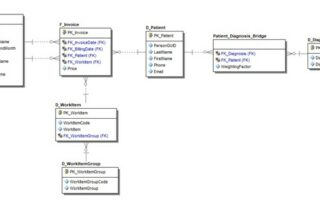
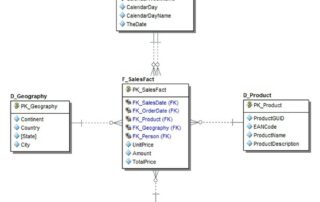
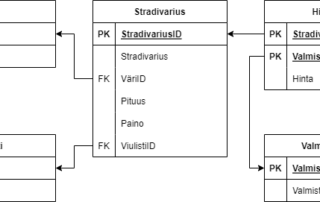
Mikä on Lakehouse tietoalustaratkaisu ja kuinka organisoida data tehokkaasti Lakehousessa?
Puhuttaessa modernista tietovarastoinnista ja sen arkkitehtuureista ei voi olla törmäämättä erilaisten tietojärvien ja tietovarastojen käsitteisiin. Tässä blogikirjoituksessa käsitellään tietoalustojen evoluutiota perinteisestä tietoalustasta ja tietovarastoinnista kohti Lakehouse-tietoarkkitehtuuria, erityisesti tarkastellen Lakehousea ja [...]