Yleisesti nimeämiskäytännöistä
Endoton suositus ja paras käytäntö kaikkien tietokantaolioiden määrämuotoiselle nimeämiselle loogisesti oliotyypin ja käyttötarkoituksen mukaan. Vältä ennen kaikkea teknisiä nimiä ja kirjainlyhenteitä niin paljon kuin mahdollista. Tärkeintä on, että koodisi on ymmärrettävää. Intellisense on olemassa pitkiäkin olionimiä varten. Puolipisteen kurinalainen käyttö statementtien lopuksi sekä koodin selkeä indentointi on myös hyvin tärkeää opetella, jotta koodi olisi mahdollisimman luettavaa.
Clean install-skriptimoduulit
Muistathan,että clean install-skriptinkin ajo voi mennä syystä tai toisesta pieleen. Tämän takia, ja jotta seuraavan tuoteversion skriptaaminen ja asentaminen olisi halpompaa, on syytä tehdä kaikista skripteistäsi uudelleenajettavia.
Tänään keskitytään Tables and views -skriptiin.
Skriptin vaiheistus
Tables and views-skriptissä (uudelleen-)luodaan nimensä mukaisesti käyttäjätaulut. Tässä vaiheessa tehdään ainakin seuraavat toimenpiteet siten, että skriptin uudelleenajettavuus on mahdollista:
- Pudotetaan käyttäjätaulujen pää- ja viiteavaimet
- Pudotetaan käyttäjänäkymät
- Pudotetaan käyttäjätaulut
- Luodaan käyttäjätaulut
- Lisätään käyttäjätauluihin constraintit ja defaultit
- Lisätään käyttäjätauluihin viiteavaimet
- Lisätään käyttäjänäkymät
- (Uudelleen-)luodaan muut kuin viiteavainindeksit
- Luodaan viiteavainindeksit
- Otetaan tarvittaessa kompressointi käyttöön
Käyttäjätaulujen pää- ja viiteavainten pudotus
Tämä homma hoituu parhaiten silmukalla. Näin säästyt turhalta koodaamiselta. Koodiesimerkissä tuhotaan 5 avainta kerrallaan niin kauan kuin avaimia riittää, näin toiminto on tehokas ja joustava eritoten, jos avaimia on satoja tai jopa tuhansia kappaleita.

Käyttäjänäkymien pudotus
Tässä ei pitäisi olla mitään sen ihmeellisempää. Käyttäjänäkymät nimetään esim. prefixillä ”v_”. If exists -määre on tietty pakollinen skriptin uudelleenajettavuutta varten ja olioviittaukset kannattaa lähtökohtaisesti kirjoittaa aina unicodena.
Käyttäjänäkymän pudotus.

Käyttäjätaulujen pudotus
Käyttäjätauluihin voi poistettaessa viitata näppärästi suoraan if exists-määreellä, niin kuin itse asiassa näkymiinkin.
Käyttäjätaulun pudotus.

Käyttäjätaulujen luonti
Käyttäjätaulujen osalta rajaan tämän blogin partitioimattomien taulujen käsittelyyn. Voisinkin kirjoittaa partitioitavista tauluista sitten ihan oman blogin, se kun on sen verran laaja kokonaisuus.
Esimerkissä luodaan käyttäjätaulu, jonka olemassaolo tarkistetaan sys.objects -näkymän kautta. Tässä on tärkeää muistaa, että taulun type -kentän tulee olla ”U”, eli käyttäjätaulu. Taulun käyttötarkoitukseen voi käyttää skeemaa tai sitten esimerkiksi kolmikirjainlyhennettä, mikäli skeemalla on esimerkiksi jokin muu käytttötarkoitus.
Taulua luotaessa sille määritellään kentät, joiden tietotyypit ja kenttäpituudet kannattaa miettiä huolella suorituskykynäkökulmasta eritoten silloin, kun taulu voi kasvaa isoksi. Joka tapauksessa kannattaa noudattaa kaikissa tietotyypeissä sekä kenttäpituuksissa johdonmukaisuuden periaatetta. Muista myös määrittää kentälle aina, voiko se saada null-arvon vai ei. Myös taulun pääavain luodaan tässä yhteydessä.
Käyttäjätaulun luonti.
Constrainttien ja default-arvojen lisäys käyttäjätauluihin
Constrainttien ja default-arvojen poistoissa viitataan sys.objects -näkymään type -kentän saadessa arvon ”D”.
Defaultin luonti.

Constraintin luonti.

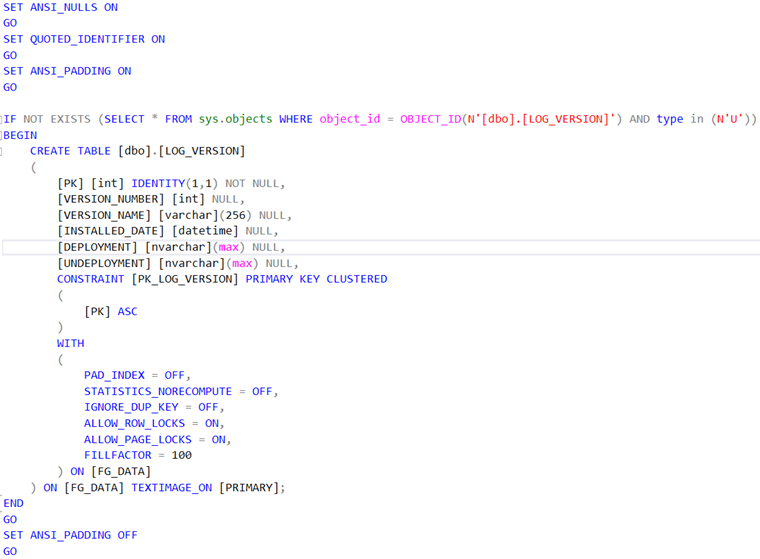
Viiteavainten lisäys käyttäjätauluihin
Viiteavainta lisättäessä NOT EXISTS -määreelle annetaan referenssi sys.foreign_keys -näkymään, josta haetaan OBJECT_ID -funktiolla viiteavaimen nimi. Tämän lisäksi parent_object_id -kentän tulee viitata käyttäjätauluun itseensä. Mahdollinen cascadointi on myös määriteltävä tässä yhteydessä. CASCADE-määre tulee antaa viiteavaimelle päivittämisen (UPDATE) ja / tai deletoinnin (DELETE) yhteyteen. Kaskasointi tarkoittaa sitä, että mikäli viitatusta päätaulusta poistuu tai siinä päivitetään arvoja, päivitykset heijastuvat myös viittaavaan tauluun. Tässä taulussa sellaista ei ole määritelty.
Viiteavaimen lisäys käyttäjätauluun.
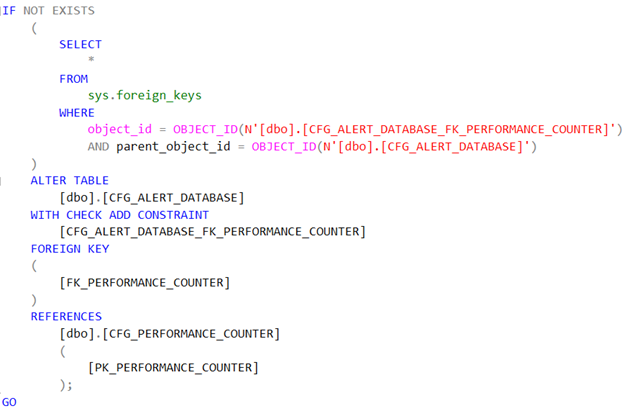
Käyttäjänäkymien lisääminen
Käyttäjänäkymien luonti on SQL Serverissä varsin suoraviivaista. Erikoisuutena voisi mainita SCHEMABINDING -option näkymää luotaessa: Se sitoo luodun näkymän pohjana olevan taulun tai taulujen rakenteeseen. Tämä on näppärää, jos haluat esimerkiksi varmistaa, että näkymät ovat aina ajantasaisia tai haluat lisätä indeksoinnin itse näkymään. Kun SCHEMABINDING on määritetty, perustaulua tai -tauluja ei voi muokata tavalla, joka vaikuttaisi näkymän määritykseen. Itse näkymämääritystä onkin ensin muokattava tai se on poistettava, jotta muokattavan taulun riippuvuudet poistetaan. Edelleen, kun käytät SCHEMABINDING:ia, SELECT:in on sisällettävä viitattujen taulujen, näkymien tai käyttäjän määrittämien funktioiden (UDF) kaksiosaiset nimet (schema.object). Kaikkien viitattujen objektien on myös oltava samassa tietokannassa.
Näkymiä tai tauluja, jotka osallistuvat SCHEMABINDING-lausekkeella luotuun näkymään, ei voi pudottaa, ellei näkymää poisteta tai muuteta niin, että sillä ei enää ole rakenteen sidontaa. Muussa tapauksessa tietokantamoottori aiheuttaa virheen. Myös ALTER TABLE -lausekkeiden suorittaminen tauluissa, jotka osallistuvat näkymiin, joissa on SCHEMABINDING, epäonnistuu, koska nämä lausekkeet vaikuttavat näkymän määritykseen.
Käyttäjänäkymän lisääminen.
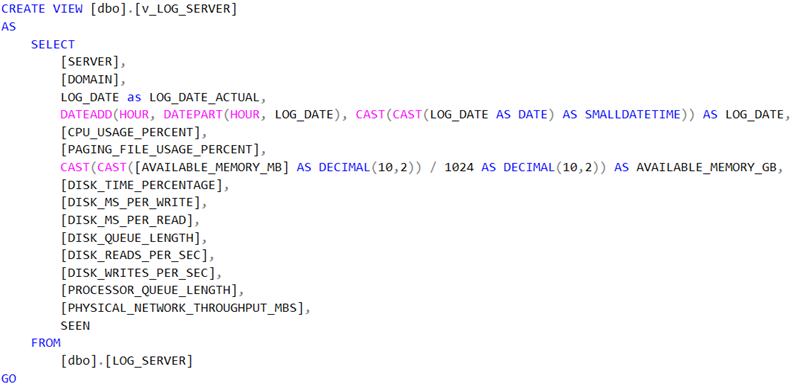
Tavallisten indeksien lisäys
Indeksi poistetaan viittaamalla suoraan indeksin nimeen NOT EXISTS -määreellä kyseisessä taulussa. Lisäyksessä on hyvä muistaa, että mm. paksussa indeksissä kenttäjärjestys on B-tree -indeksin fyysinen järjestys ja että on mahdollisesti väliä sillä, kummassa järjestyksessä kunkin kentän indeksi fyysisesti organisoidaan (ASC vs. DESC).
Indeksin täyttöaste (fillfactor) on arvioitava sen muutosherkkyyden perusteella. Muuttumaton data, joka vain kerran kirjoitetaan tauluun ja sitä sitten selectoidaan, voi saada 100% täyttöasteen, mutta muutoin se on tyypillisesti välillä 60-95%. Oikein valittu täyttäaste voi vähentää mahdollisia page splittejä tarjoamalla riittävästi tilaa indeksin laajentamiselle, kun tietoja lisätään tauluun. Kun uusi rivi lisätään täydelle indeksisivulle, tietokantamoottori siirtää noin puolet riveistä uudelle sivulle, jotta tuolle riville jää tilaa. Tätä uudelleenjärjestelyä kutsutaan page splitiksi. Page split tekee tilaa uusille tietueille, mutta sen suorittaminen voi viedä aikaa ja vaatii paljon resursseja. Lisäksi se voi aiheuttaa fragmentaatiota, joka lisää storagen I/O-aktiviteettia. Jos sivujakoja tapahtuu usein, indeksi voidaan muodostaa uudelleen käyttämällä uutta tai aiemmin luotua fillfactor-arvoa tietojen jakamiseksi uudelleen. Esimerkin indeksisivuun kohdistuu kohtalaisesti UPDATE– / DELETE -toimintaa.
Indeksin lisäys.
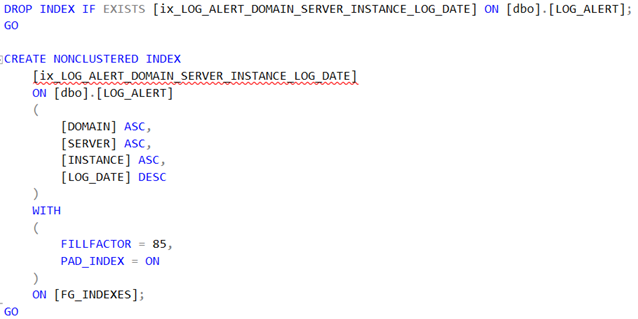
Viiteavainindeksien lisäys
Viiteavaimia voi olla todella paljon ja kun ne on nimetty systemaattisesti samalla prefixillä, on varsin triviaalia automatisoida viiteavainindeksien lisäys. Esimerkkiskriptissä on tosin vakio täyttöaste indeksille, joten voit halutessasi optimoida skriptiä hieman pidemmälle.
Viiteavainindeksien automaattinen lisäys iteraattorilla.

Kompressoinnin käyttöönotto tietokannassa
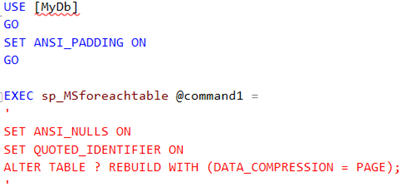
Taulukompressointi säästää tilaa helposti tietokannassa jopa 50% ja sen CPU-footprint on 1% luokkaa, joten se kannattaa ottaa ehdottomasti käyttöön. Kompressointia on tarjolla rivitasolla (ROW) ja sivutasolla (PAGE). Yleensä sivutason kompressointi on tehokkaampi, eritoten datamart-tyyppisissä denormalisoiduissa tietokantaskeemoissa. Kompressoinnin hyötyä voi myös arvioida sp_estimate_data_compression_savings –systeemiproseduurilla. Proseduuri on tosin aika hidas isoja tauluja vasten ja jos tauluja on paljon, kannattaa joko automatisoida koko prosessi acceptance test -ympäristössä tai sitten käyttää aina rekursiivisesti PAGE -tason kompressointia, joka kokemukseni mukaan on 90-prosenttisesti oikea vaihtoehto. Kokeiltuasi eri vaihtoehtoja todennäköisesti päädyt seuraavaan ratkaisuun:
Loppusanat
Tietokantaskripteissä on hallinnallisesti neljä dimensiota: Systemaattisuus vs. luovuus ja dynaamisuus vs. staattisuus. Luovuuden ja dynaamisuuden kasvaessa koodin luettavuus ja ylläpidettävyys usein kärsivät, mutta toisaalta selviät paljon vähemmällä koodilla ja voit tehdä automaatioita aivan uudella tavalla. Your choice!
Tarvitseeko tiimisi auttavia, kokeneita DBA-käsipareja? Ole hyvä ja ota meihin yhteyttä!

Jani K. Savolainen
jani.savolainen@dbproservices.fi
0440353637
VP & Chairman
DB Pro Services Oy