
Tämä blogi kertoo siitä, miksi juuri sinun tulisi käyttää Power BI:tä vuonna 2024 liiketoiminnassasi ja mitkä ovat työkalun tärkeimmät ominaisuudet. Kirjoituksen luettuasi osaat vastata siihen, mikä Power BI on, miksi se on parempi ratkaisu analytiikkaan kuin Excel, sekä mitä kustannuksia työkalun käyttöönotosta tulee.
Mikä Power BI on?
Lyhyesti sanottuna Power BI on Microsoftin kehittämä tehokas liiketoimintatiedon analysointi- ja visualisointityökalu, joka mahdollistaa suurten tietomäärien hallinnan ja niiden muuttamisen ymmärrettäviksi raporteiksi ja visuaalisiksi esityksiksi. Sen intuitiivinen käyttöliittymä ja kyky integroitua monenlaisiin tietolähteisiin tekevät siitä erinomaisen valinnan erikokoisille organisaatioille, jotka haluavat tehdä tietopohjaisia päätöksiä. Power BI:n suosio kasvaa jatkuvasti, ja se on laajalti tunnustettu yhdeksi markkinoiden johtavista business intelligence -työkaluista. Business Intelligence (BI) -työkalut fasilitoivat liiketoiminta datan keruuta, prosessointia, analysointia ja visualisointia. Power BI on ollut markkinajohtaja BI-työkaluissa 16 peräkkäistä vuotta (2023 Gartner® Magic Quadrant™ I Microsoft Power BI).
Power BI:n tärkeimmät määrittävät ominaisuudet ovat datan integrointi, datan prosessointi, datan analysointi, datan mallinnus ja datan visualisointi. Datan integrointi viittaa tässä Power BI:n kykyyn ottaa yhteyttä lukuisiin erilaisiin datalähteisiin, kuten erilaisiin tietokantoihin, taulukkolaskentaohjelmiin ja liiketoiminta applikaatioihin. Power BI:ssä on tätä prosessia varten lukuisia valmiiksi rakennettuja datayhdistimiä.
Datan prosessointi viittaa tässä artikkelissa kaikkiin muutoksiin mitä lähdedataan tehdään, jotta sen pohjalta voidaan tehdä analytiikkaa. Power BI:n moottori tätä prosessia varten on Excelistä tuttu Power Query. Kaikki muutokset, mitä Power Queryssä tehdään, ilmaistaan Power BI:ssä M-kielen avulla.
Datan mallinnus on prosessi, jossa rakennetaan malli datan rakenteesta ja suhteista. Power BI toimii tehokkaimmillaan, kun data mallinnetaan tähtimalliin, jossa keskitetyt faktatiedot yhdistyvät suorilla suhteilla dimensiotietoihin. Power BI data-analytiikkakieli (DAX) on tehokkaimmillaan siloin, kun data on mallinnettu tällä tavalla.
Datan analysointi tapahtuu Power BI:ssä edellä mainitulla DAX-kielellä. Erilaiset analysoitavat liiketoimintalogiikat voidaan ilmaista DAX:in avulla koodimuodossa. Hyödyntämällä tehokasta visualisointia loppukäyttäjä saa nopeasti ja tehokkaasti kokonaisvaltaisen kuvan siitä, miten hänen liiketoimintansa kehittyy.
Datan visualisointi on prosessi, jossa muokattu ja liiketoimintalogiikalla rikastettu data esitetään intuitiivisesti niin, että loppukäyttäjä voi sisäistää monimutkaisia lukuja yhdellä silmäyksellä. Erilaiset visualisaatiot soveltuvat erilaisiin tarkoituksiin. Näyttäessä lukujen muutosta ajan yli viivadiagrammi on hyvä valinta. Vertaillessa kahden kustannuspaikan välisiä eroja pylväsdiagrammi osoittaa hyvin kategorioiden välisiä eroja. Tutkiessa kustannusten jakaumaa dimensioden yli piirasdiagrammi toimii moitteettomasti.
Miksi Power BI on paras vaihtoehto BI analytiikkaan?
Business Intelligenceä (lue data-analytiikkaa) voi kähtökohtaisesti lähestyä kolmesta eri kulmasta, jollet halua koodata omaa ratkaisuasi. Nämä vaihtoehdot ovat: Taulukko-ohjelma, valmiiksi rakennettu ohjelmisto tai BI-työkalu. Koitan nyt perustella, miksi sinun tulisi käyttää BI-työkalua näistä kolmesta vaihtoehdosta.
Oletetaan tilanne, jossa haluat tutkia miten liiketoiminnallasi menee. Mietitään, miten lähestyisit asiaa näillä kolmella eri työkalulla. Ensimmäinen vaihtoehtosi on ottaa esiin tuttu ja turvallinen Excel. Jotta voit analysoida lukuja mitä haluat tutkia, joudut joko kopioimaan luvut katsomalla ERP:iäsi ja kirjaamalla numerot manuaalisesti tai käyttämällä aikaisemmin mainittua Power Queryä. Toivottavasti et kopioi lukuja manuaalisesti, sillä inhimillisen virheen riski on suuri. Käyttämällä Power Queryä saat luvut kätevästi käyttöön ja analytiikkaa rakennettua. Seuraava haasteesi on lukujen jakaminen. Excel ei ole suunniteltu yhteiskäyttöön ja vaihtoehtonasi on lähettää tiedosto itsessään eteenpäin sähköpostilla tai siirtää Excel esimerkiksi OneDriveen. Molemmissa lähestymisissä on haasteena se, että henkilöt joille jaat tiedoston, voivat muokata sitä helposti. Tämä kuulostaa hyvältä, mutta sisältää riskejä. Olen kuullut lukuisia kertomuksia, joissa excel-tiedostoja ei uskalleta avata, koska pelätään, että “saatan rikkoa sen vahingossa niin en halua avata sitä”. Excel on siis helppokäyttöinen, mutta riskialtis muokattavuutensa takia. Tämän lisäksi sen ylläpitäminen sisältää paljon manuaalista työtä, ja kun haluat päivittää numeroita, joudut manuaalisesti hakemaan uudet datat.
Toinen vaihtoehtosi on käyttää valmiiksi rakennettua softaa, jonka jokin kooditalo on rakentanut. Ohjelmisto voi olla helppokäyttöinen ja se on vaikea ellei mahdoton rikkoa, mutta ongelmaksi muodostuu muokattavuus. Koska ohjelmisto ei todennäköisesti ole kehitetty juuri sinun firmallesi, vaan myytäväksi usealle organisaatiolle sen liiketoimintalogiikka ei todennäköisesti vastaa sinun liiketoimintaasi. Tapa jolla hinnoittelet tuotteesi saattaa poiketa kilpailijoistasi ja kustannuspaikkasi saattavat sisältää sellaisia dimensioita, mitä alkuperäisessä ratkaisussa ei otettu huomioon. Jotta saat kaiken irti ohjelmistosta, joudut ostamaan siihen kustomointia, mikä on usein erittäin kallista.
Kolmas vaihtoehtosi on käyttää BI-työkalua. Kuten Excelissä, pystyt käyttämään Microsoftin Powerqueryä datan muokkaamiseen. Voit rakentaa liiketoimintalogiikkasi DAX:in avulla juuri sinun liiketoimintasi mukaiseksi. Erona Exceliin on raportin jakaminen. Power BI-raportin voi julkaista Power BI serviceen, missä kaikki, kenelle haluat jakaa raportin, pääsevät katsomaan sitä tietoturvallisessa ja yksiselitteisessä sijainnissa. Jos et halua, että raporttia voi muokata, voit rajata muiden käyttäjien oikeuksia. Tällä tavoin raporttia ei saa rikki, ja kaikki voivat puhua liiketoiminnasta samoilla luvuilla. Power BI service tukee myös datan automaattipäivityksiä ja voit määrittää esimerkiksi, että raportti hakee uudet datat joka yö.
Miten voit ottaa Power BI:n käyttöön?
Power BI:n voi ottaa koekäyttöön ilman kustannuksia lataamalla Power BI desktopin. Jotta voit jakaa raportteja organisaatiossasi tarvitset lisenssin. Lisennssivaihtoehtoina on Power BI pro, Power BI premium käyttäjille tai Power BI premium/Fabric kapasiteetti. Pienille ja keskisuurille yrityksille kustannustehokkain vaihtoehto on usein Power BI pro lisenssien hankinta käyttäjille ketkä seuraavat raportteja. Nämä lisenssit maksavat noin 10 euroa per käyttäjä kuukaudessa.
Raporttien kehittämisessä on muutamia sudenkuoppia, jotka liittyvät Power BI:n ja Excelin välisiin eroihin. Modernoidessa raportteja on hyvä olla tietoinen miten DAX:in “suodatinkonteksti” toimii laskentaa arvioidessa. Hieman teknisemmin sanottuna Excelin laskenta perustuu niin sanottuihin visuaalisiin kaavoihin, kun taas Power BI:n laskenta perustuu edellä mainittuun suodatinkontekstiin.
Esimerkki
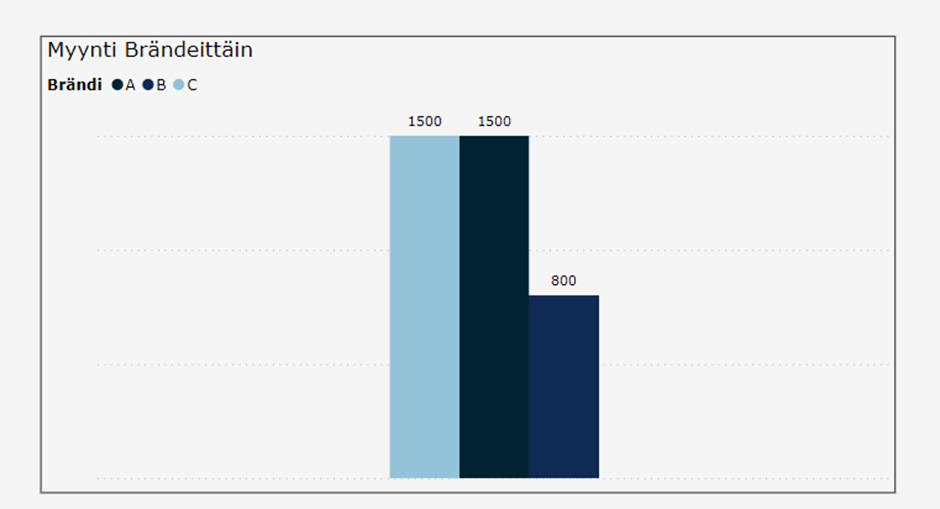
Tavoitteena on laskea kokonaismyynti siten, että myyntimäärä kerrotaan myyntihinnalla.
| Määrä | Hinta | Brändi |
| 100 | 1 | A |
| 200 | 2 | A |
| 500 | 2 | A |
| 200 | 4 | B |
| 300 | 5 | C |
Excel:
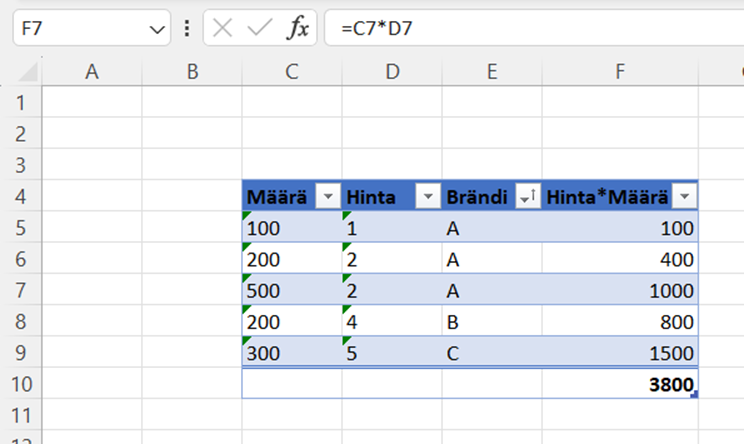
Koska DAX ei perustu visuaalisiin laskentoihin, yrittäessä samaa laskentaa Power BI:ssä, ohjelma antaa seuraavan virheen:

Käyttämällä ehotettua korjausta kaava alkaa näennäisesti toimimaan, mutta jostain syystä totaali näyttää omituiselta:
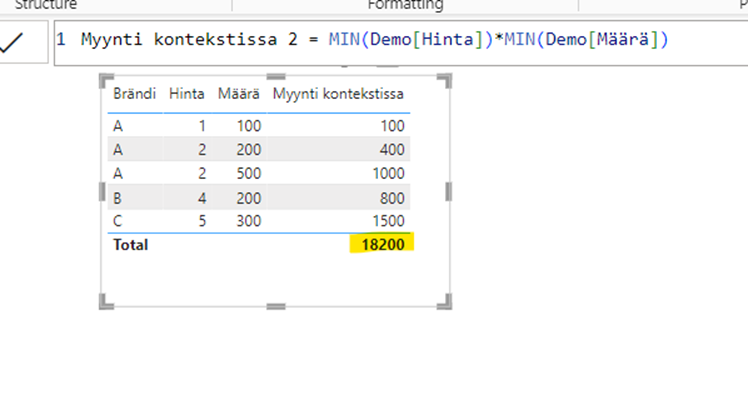
Tämä käyttäytyminen on esimerkki laskentalogiikan erosta. Excel laskee summan solujen F5:F9 välillä, mutta Power BI laskee totaalin “tyhjässä laskentakontekstissa”. Käytännössä tämä tarkoittaa sitä, että Power BI aggregoi luvut niin, että brändiä ei ole määritelty. (1+2+2+4+5) * (100+200+500+200+300) = (14)*(1300)=18200
Huomioimalla laskentalogiikan ja käyttämällä eri kaavaa luvut täsmäävät:
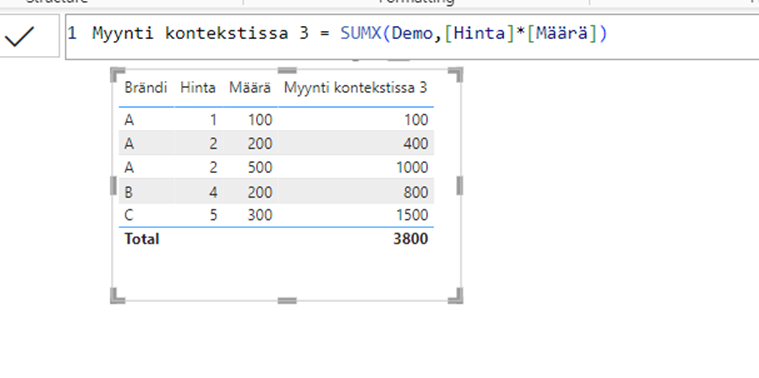
Nyt, kun laskentalogiikka on huomioitu, voimme helposti muokata visuaalia ja pääsemme hyödyntämään Power BI:n ominaisuuksia. Voimme esimerkiksi poistaa turhat sarakkeet:
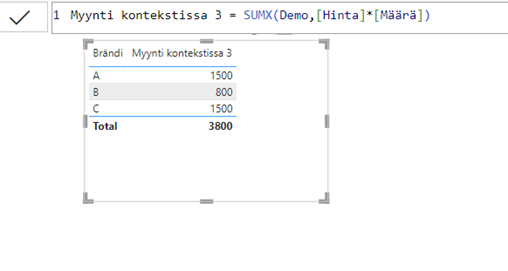
…ja muuttaa taulukon pylväsdiagrammiksi:
Yhteenveto
- Power BI on Microsoftin kehittämä BI-työkalu, joka tarjoaa käyttäjilleen tapoja toteuttaa kaikki tarvittavat data-analytiikan prosessit.
- Power BI:n avulla saat parhaat puolet helposti muokattavasta Excelistä ja robusteista SaaS-pohjaisista analytiikkaratkaisuista. Ohjelma on helposti muokattava ja mukautuu liiketoimintaasi, mutta sen käyttö on luotettavampaa ja läpinäkyvämpää, kuin helposti rikkoutuvat Excel-ratkaisut.
- Power BI:n lisenssit ovat halvimmillaan 10e/kk/käyttäjä
Kun ohjelmiston laskentalogiikan hallitsee, sen avulla voi rakentaa nopeasti näyttäviä ja informatiivisia visualisointeja.
DB Pro Services tarjoaa kattavia ratkaisuja ja asiantuntijapalveluita tiedolla johtamisen haasteisiin. Tarjontamme kattaa muun muassa datastrategian, modernien data-alustojen, sekä edistyneen analytiikan kokonaisuudet, kuin myös vaativat datamigraatiot. Ota yhteyttä, niin autamme sinua ja organisaatiotasi hyödyntämään tietoa tehokkaasti ja menestymään kilpailussa!
Valtteri Nättiaho
Lead Data Analyst
Valtteri.Nattiaho@dbproservices.fi
DB Pro Services Oy
Microsoft julkaisi Build 2023 tapahtumassa toukokuun lopussa uuden data- ja analytiikka-alustan, Microsoft Fabricin, joka yhdistää keskeisimmät Microsoftin data- ja analytiikkakomponentit yhteen pilvipalveluun. Fabricin tavoitteena on yksinkertaistaa, mutta myös demokratisoida tapaa, jolla organisaatiot hyödyntävät ja jakavat dataansa.
OneLake kaiken perustana
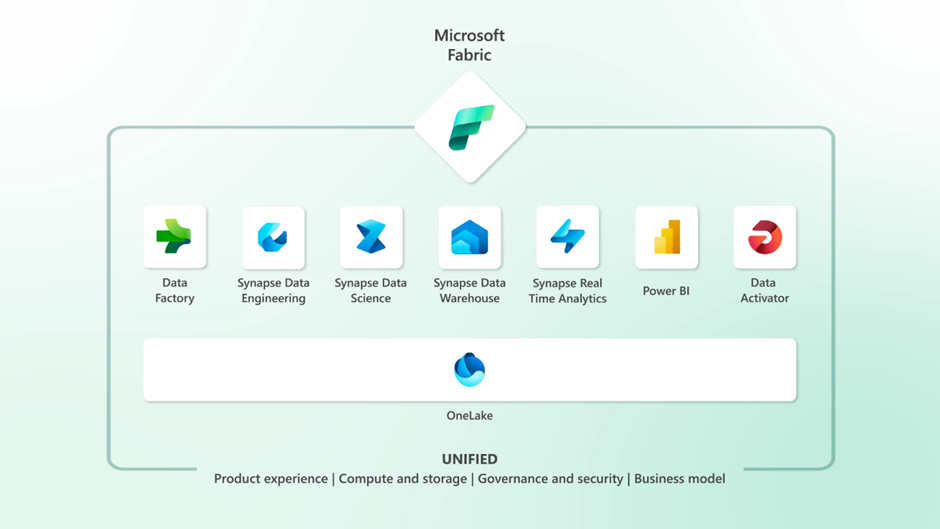
Fabricin arkkitehtuuri rakentuu OneLaken päälle, joka on organisaationlaajuinen, keskitetty datan tallennustila. OneLakea voidaan laajentaa yhdistämällä siihen erillisiä Azuren tai Amazonin datan tallennustiloja. Myös Google Cloud -integraatiomahdollisuus on tulossa myöhemmin. OneLakeen liitetyt dataresurssit ovat käytettävissä niiden käyttöoikeusmäärittelyjen rajoissa ja OneLaken merkittävin ominaisuus onkin se, että sen avulla käyttäjän ei tarvitse tietää organisaation omistamien datalähteiden sijaintia, vaan ne kaikki ovat saatavilla yhdestä paikasta.
Kuvan lähde: https://azure.microsoft.com/en-us/blog/introducing-microsoft-fabric-data-analytics-for-the-era-of-ai/
Fabric käytännössä
Fabric on siis käytännössä sateenvarjo, jossa yhden käyttöliittymän kautta voidaan käyttää useita palveluita. Tällä hetkellä Fabric sisältää seuraavat komponentit ja työkuormat:
- Datan tallennukseen jo yllä mainittu OneLake
- Integraatiot ja orkestrointi tapahtuu Data Factoryn avulla
- Synapsesta tutut komponentit:
- Data Engineering
- Data Warehousing
- Real-Time Analytics
- Data Science
- Analytiikka tapahtuu Power BI:llä
- Governance ja lineage hoidetaan Purview’n avulla
- Tapahtumaperusteiset toiminnot ja hälytykset Data Activatorin kautta
Fabricin sisältämät työkuormat jakavat saman laskentakapasiteetin, joka on tarpeen mukaan skaalattavissa. Laskentakapasiteetti on siten aina saatavissa, kun sitä tarvitaan. Ei siis enää ennalta varattua kapasiteettia ja sen ohjelmallista tai manuaalista sammuttelua kustannusten säästämiseksi.
OneLake mahdollistaa myös eri työkuormien välisen datan jakamisen ilman kopiointia tai siirtämistä paikasta toiseen: Lakehouse-kannassa olevaa dataa voidaan hyödyntää Warehouse-kannassa ja toisinpäin, mutta se on suoraan luettavissa myös Power BI -datasettiin. Huolimatta siitä, käytetäänkö Lakehouse vai Warehouse -arkkitehtuuria, data tallennetaan OneLakeen aina avoimessa Delta/Parquet muodossa. Fabricissa muodostuu automaattisesti jokaiselle Lakehouselle SQL-rajapinta, mitä kautta dataa voidaan kysellä suoraan käyttäen T-SQL komentoja.
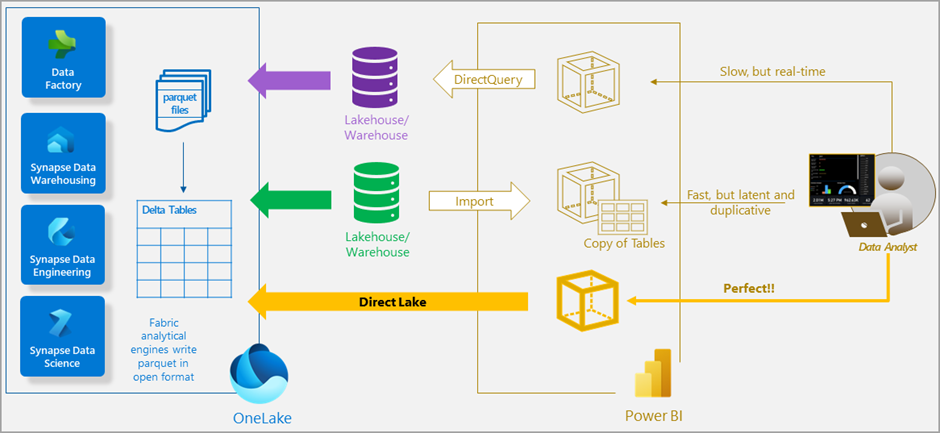
Suora yhteys tiedostoihin -Direct Lake
Fabricin myötä myös Power BI sai tehokkaan ominaisuuden lukea OneLaken Deltatauluja suoraan, mahdollistaen lähes reaaliaikaisen ja erittäin suurten datamassojen analysoinnin. Direct Lake toimii kuten DirectQuery, mutta se on optimoitu OneLaken Deltataulujen lukemiseen. Direct Lake yhdistää DirectQueryn ja Import moden parhaat puolet; data on saatavissa välittömästi, kun se on tallennettu OneLakeen, suorituskyvyn säilyessä parhaalla mahdollisella tavalla.
Kuvan lähde: https://learn.microsoft.com/en-us/power-bi/enterprise/directlake-overview
Yksinkertainen käyttöoikeushallinta
Fabricin käyttäjänhallinta on tuttu Power BI:n käyttäjänhallinnasta, käyttäjien oikeudet määritellään jokaiselle työtilalle erikseen ja myös työtilan sisällä voidaan rajoittaa käyttäjien oikeuksia Power BI objekteihin, SQL-rajapintoihin ja Warehouse-kannan sisällä oleviin objekteihin. Nykyinen Power BI:n tietuetason tietoturva toimii kuten ennenkin, Fabric ei muuta sen toimintatapaa.
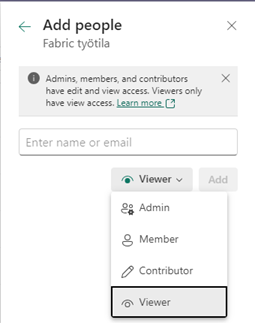
Työtilassa käyttäjille voidaan asettaa oikeuksia seuraavien roolien kautta:
- Admin, työtilan sisällä oikeus kaikkeen
- Member, työtilan sisällä oikeus kaikkeen muuhun, paitsi työtilan poistoon ja tiettyjen käyttäjäroolien muokkaukseen
- Contributor, työtilan sisällä oikeus laajaan sisällöntuottamiseen
- Viewer, työtilan sisällä oikeus käyttää objekteja
Tarkemmat roolikuvaukset löytyvät Microsoftin sivuilta.
Fabric kapasiteetti
Tällä hetkellä Fabric kapasiteettia voi hankkia kahdella eri tavalla:
- Azure, laskutus käytön mukaan. Ei sitoutumista
- Microsoft 365, laskutus kuukausittain tai vuositasolla
Azuren hinnoittelussa on sijaintikohtaisia eroja ja tällä hetkellä Fabric kapasiteetin hinnoittelu North Europessa näyttää tältä:
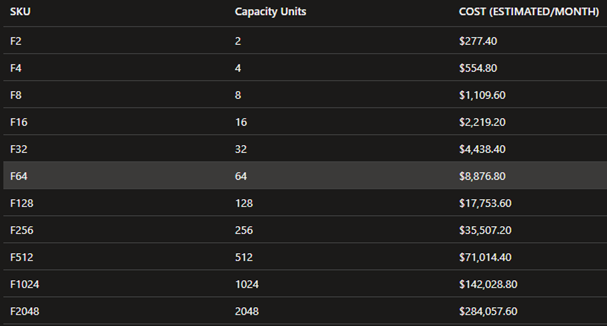
Ja West Europessa tältä:
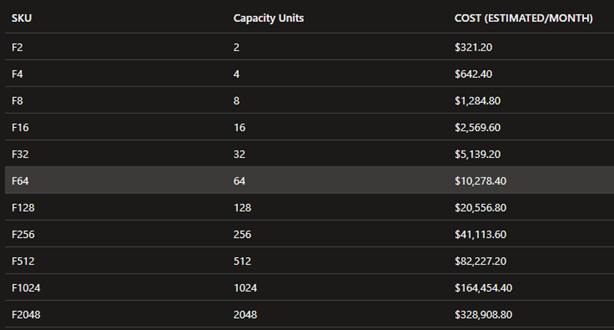
Hinnat voivat kuitenkin muuttua, mutta tärkeintä tässä on ymmärtää se, että vaikka kapasiteetin sijainnilla voi vaikuttaa suoraan sen hintaan, voi eri sijaintien väliset datansiirtokulut nousta merkittävästi, jos organisaatiolla on useita tallennustiloja, dataa on paljon ja käyttö aktiivista. OneLaken tallennustila aiheuttaa kustannuksia tallennetun datan määrän mukaan, mutta myös mahdollisten maantieteellisten sijaintien välisestä datansiirrosta aiheutuvat kulut lisätään OneLaken kustannuksiin. Tällä hetkellä kustannusten ennustamiseen ei ole tarjolla laskuria, vaan kapasiteetin koon arviointi tapahtuu käytännössä kokeilemalla eri vaihtoehtoja omien työkuormien avulla.
Microsoft Fabric – mitä jäi käteen?
Ottaen huomioon sen potentiaalin, jota Fabricissa on ja markkinoiden asettamat vaatimukset, uskon, että Fabric tulee vaikuttamaan laajasti organisaatioiden datastrategiaan tarjoamalla kokonaisvaltaisen Data- ja analytiikkaratkaisun SaaS-palveluna.
Fabricin laajennettavuus sisältämään olemassa olevat pilvipohjaiset datan tallennusratkaisut kaikissa johtavissa pilvialustaratkaisuissa (Azure, Amazon, Google Cloud), poistaa datan siiloutumisen sekä tuo organisaation datan kaikkien saataville, käyttäjän roolista riippumatta. Laajennettavuus mahdollistaa myös tietolähteiden hajauttamisen ilman monimutkaisia ja dataa kopioivia integraatioita, joten kaikkia munia ei tarvitse pitää samassa korissa.
Organisaatioiden analytiikan self-service-kyvykkyydet paranevat, kun data on käytettävissä keskitetystä tietolähteestä ja avoimella formaatilla. Myös nykyiset Data-alustaratkaisut Azuren erillisillä palveluilla voidaan siirtää Microsoft Fabricin työkuormiksi, joka mahdollistaa yksinkertaisemman palvelunhallinnan ja yhdenmukaisen kulurakenteen.
Kiinnostuitko aiheesta? Ota yhteyttä, niin jutellaan lisää!
Tommi Vallinmäki
Senior Data Engineer & Architect
tommi.vallinmaki@dbproservices.fi
DB Pro Services Oy
Robin Aro
Lead Data Engineer
robin.aro@dbproservices.fi
DB Pro Services Oy
Tutustu myös blogeihimme:
Power BI-raportointi – tasapaino tekniikan ja muotoilun välillä
Tehot irti BI-analytiikasta, Power BI vuonna 2024
Tietoalustojen ja pilviteknologioiden kehityksen myötä yritykset panostavat tietoon perustuvaan päätöksentekoon. Tietoa käsitellään ja säilötään kasvavissa määrin erilaisten järjestelmien ja tietovarastojen sisällä. Tietojen käsittelyä tapahtuu useissa eri järjestelmissä, kuten erilaisissa toiminnanohjaus- (ERP), laskutus- ja asiakkuudenhallintajärjestelmissä (CRM). Näillä järjestelmillä on jatkuvasti yhtäaikaisia käyttäjiä, jotka samanaikaisesti muokkaavat ja päivittävät tietoa. Lisäksi tiedot ja tietojenkäsittely ulottuvat usein yli organisaatiorajojen, mikä voi johtaa tiedon tuplaantumiseen, vanhentumiseen tai pirstaloitumiseen. Tällaiset tiedon laadulliset ongelmat aiheuttavat epätarkkuuksia tärkeissä analyyseissa ja raporteissa. Vastaukset liiketoiminnalle tärkeisiin kysymyksiin esimerkiksi asiakassegmenteistä tai tuotteiden varastomääristä vääristyvät. Tämä on myrkkyä liiketoiminnalle ja tietoon pohjautuvalle päätöksenteolle.
Vasta-aineena ydintietojen eli Master Datan määrittely ja Master Datan hallinta
Yllä mainittua ongelmaa on hyvä lähestyä tiedonhallinnallisesti ja tarkkaan laaditulla data strategialla. Ensin tulee määritellä ja erottaa yrityksen tietokokonaisuudesta ydintietoelementit eli Master Data.
Perinteisesti Master Datan katsotaan sisältävän yrityksen kriittisiä tietokokonaisuuksia, kuten asiakas-, tuote-, toimittaja- ja työntekijätietoja, joita käytetään johdonmukaisesti eri liiketoimintaprosesseissa ja sovelluksissa. Kaikkia näitä tietoja yhdistää se, että tähän dataan kohdistuu harvoin muutoksia ja tieto on luonteeltaan pysyvää pitkäaikaista tietoa.
Master Datan määrittelemiseen ja tunnistamiseen on hyvä käyttää käsitemallinuksen metodeja. Käsitemallilla tarkoitetaan geneeristä liiketoimintalähtöistä tietomallia, jota käytetään tietoalueen tietojen kuvailemiseen ja niiden suhteiden syvälliseen ymmärtämiseen. Käsitemallinnuksella saadaan eroteltua ja tunnistettua Master Data ja tapahtumatyyppinen data toisistaan. Mallin avulla luot perustan yrityksen yhteiselle kielelle, kun puhutaan datasta ja tietoelementeistä.
Master Dataa ei tule kuitenkaan sekoittaa referenssidataan, jolla tarkoitetaan myös luonteeltaan pysyvää tietoa. Yleisesti referenssidatalla tarkoitetaan ulkoisia standardoituja koodistoja, kuten maa-, kunta- tai muita vastaavia koodistoja, joita yleensä hyödynnetään tietovarastossa tietokokonaisuuksien laajentamiseen.
Kuinka edetä, kun Master Data on määritelty
Master Datan hallinnalla (MDM) tarkoitetaan erilaisia prosesseja ja työkaluja, joilla varmistetaan Master Datan hallinta ja koordinointi koko yrityksessä. MDM-arkkitehtuuri tuleekin suunnitella vastaamaan organisaation erityistarpeita, jotta ydintiedot ovat tarkkoja ja käytettävissä kaikkialla yrityksessä.
Käytännössä suunnitellaan keskitetty tietovarasto Master Datan hallintaan ja tallennetaan Master Data tähän yhteen keskitettyyn tietovarastoon. MDM-tietovarasto integroituu kaikkiin tietolähteisiin, jotka hyödyntävät ydintietoja. Tietolähdejärjestelmät lukevat ja kirjoittavat Master Datan MDM-tietovarastosta. Hyvin suunniteltu ja toteutettu MDM-arkkitehtuuri auttaa yritystä saavuttamaan tiedonhallintatavoitteensa ja edistämään liiketoiminnan tuloksia.
Alla oleva kuva havainnollistaa Master Datan hallinnan ja Master Datan tärkeyttä Business Intelligence (BI) tietovarastoinnin yhteydessä.
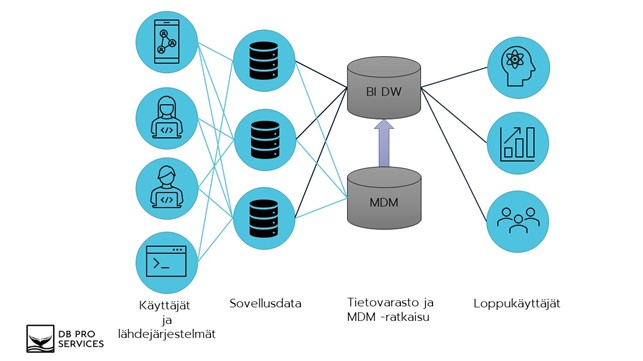
- Käyttäjät kirjaavat, päivittävät ja poistavat tietoja erilaisissa järjestelmissä. Tiedot tallentuvat näiden operatiivisten järjestelmien tietokantoihin.
- Käyttäjä saattaa olla esimerkiksi verkkosivustolla asioiva asiakas, yrityksen työntekijä tai automaattisesti rajapintaa käyttäen päivittyvä rekisteri tai laskutieto.
- Keskitetty Master Datan tietovarasto integroituu erilaisten API-rajapintojen avulla operatiivisten järjestelmien tietokantoihin.
Master Dataksi tunnistetut tiedot luetaan ja ylläpidetään operatiivisista järjestelmistä keskitetyssä Master Datan tietovarastossa muiden sovellusten ja BI-tietovaraston hyödynnettäväksi. Tällä tavalla varmistetaan, että jokaisella järjestelmällä on käytössään yksi ja ajantasainen ydintietojen kokonaisuus. - Operatiivisista tietokannoista muut liiketoiminnalle tärkeät tiedot luetaan keskitettyyn BI- tietovarastoon erilaisten Extract Transform and Load (ETL) -menetelmien avulla suoraan lähdejärjestelmien tietokannoista.
- Master data luetaan BI-tietovarastoon keskitetystä Master Datan hallinnan tietovarastosta. Näin taataan, että raportoinnin ja analytiikan käytössä olevat ydintiedot ovat yksi todellisuus, joka on aina ajan tasalla ja tärkeimmät mittarit antavat oikeita ja tarkkoja arvoja.
- Viimeiseksi Master Data on yhdistettävissä muuhun yrityksen tietoon BI-tietovarastosta. BI-tietovarastosta tiedot ovat hyödynnettävissä erilaisille hyödyntäjille, kuten edistyneelle analytiikalle tai raportoinnille.
Yhteenveto
Toimivan Master Data ja MDM-strategian toteuttaminen osana BI-arkkitehtuuria tuottaa lukuisia etuja yritykselle. Alla listattuna vielä tärkeimpiä Master Datan ja MDM:n tuottamia etuja:
- Tiedon laatu (Data Quality):
- Master Data toimii perustana tiedon laadulle tarjoamalla tarkkoja ja johdonmukaisia tietoelementtejä.
- MDM-prosessit varmistavat, että Master Data pysyy laadukkaana, tiedon laatuun liittyviä ongelmia tunnistetaan ja ne ratkaistaan.
- Master Datan hallinnan avulla yrityksen Master Datan laatu on yhtenäistä ja käytössä yhtenä totuutena koko yrityksessä.
- Erilaiset raportit ja edistynyt analytiikka sisältää usein monimutkaisia kyselyitä ja analyyseja, joille tarkka ja johdonmukainen Master Data antaa vahvan perustan.
- Tietojen hallinta (Data Governance):
- MDM-prosessit tarjoavat tarvittavan hallintokehyksen Master Datan tehokkaaseen hallintaan ja tiedon laadun ylläpitämiseen koko tiedon elinkaaren ajan.
- Master Datan määrittelyllä luodaan perusta yrityksen tietojen hallinnalle. Master Datan määrittelyn jälkeen yrityksellä on vankka pohja siirtyä muiden tietoelementtien määrittelemiseen.
- Tietojen hallinnalla varmistetaan liiketoiminnan yhtenäinen kieli yrityksen tietoelementeistä keskusteltaessa.
Me DB Pro Servicellä tarjoamme laadukkaita tietovarastoinnin ja tiedon mallintamisen asiantuntijapalveluita. Pidämme huolta, että ratkaisumme ovat kestävästi, turvallisesti ja kustannustehokkaasti toteutettuja. Ota yhteyttä ja kysy lisätietoja tarjoamistamme pilvipohjaisista moderneista tietoalusta -ratkaisuista.
Yhteistyöterveisin,
Robin Aro
Lead Data Engineer
robin.aro@dbproservices.fi
DB Pro Services Oy
Lue myös intro tietomallinnukseen

”Onnistuu” tai ”selvitetään, miten saadaan tämä onnistumaan”, sanoo uusin työntekijämme Jani Haverinen. Tämä Data Platform Engineer liittyi joukkoomme elokuussa 2021 ja tuo mukanaan erityisesti Snowflake-osaamista, minkä lisäksi Azuren datapalvelut ovat Janille hyvin tuttuja.
Peruskomponentit projekteissa ovat Janin mukaan yleensä hyvin samankaltaisia. ”Tietovarasto/tietokanta ja raportointityökalu ovat olennaisimmat komponentit. Lisäksi tarvitaan osaamista erilaisista integraatioista, datan siivouksesta ja mallintamisesta.” Janilla onkin kokemusta näistä kaikista SQL:n, Data Vault:in, Power BI:n ja Pythonin muodossa.
”Luotettavuus”, Jani vastaa, kun häneltä kysytään, mikä on data-alustan tärkein ominaisuus. ”Meistä jokainen on varmasti kironnut jossain vaiheessa jotain laitetta tai sovellusta, joka kaatuu tai ei toimi kuten pitäisi. Jos tällaista tapahtuu muutamankin kerran, niin nopeasti menevät työkalut vaihtoon. Ei siinä auta hienot visualisoinnit tai viimeisimmät koneoppimisalgoritmit, jos data ei ole validia tai integraatio hajoaa.” Samaa luotettavuutta Jani vaatii järjestelmien lisäksi myös itseltään.
Janille mahdollisuus päästä oppimaan todella kovilta tekijöiltä oli varmasti merkittävin tekijä, kun hän valitsi DB Pro Servicen työnantajakseen. ”Muutenkin itselle piirtyi sellainen kuva, että täällä kehittymiseen panostetaan ja omaa uraa pääsee viemään juuri siihen suuntaan, mihin oma kiinnostuneisuus osoittaa. Pienehkössä yrityksessä pääsee myös heti ottamaan vastuuta, mikä sopii itselle paremmin kuin hyvin.”
Vapaa-ajalla Jani haastaa itseään monessa eri urheilulajissa: ”Jalkapallo, frisbeegolf, pyöräily, tennis, jooga, kehonpainoharjoittelu… Rakastan liikkua ja kaikki kehollinen toiminta sopiikin hyvin aivotyön vastapainoksi.” Itsensä ylittäminen ja kehittäminen näkyvät myös Janin harrastuksissa: ”Onhan se vaan niin siistiä, kun oppii uusia asioita tai huomaa kehittyneensä. Pakko myös myöntää, että itsensä voittamisen lisäksi muiden voittaminen on palkitsevaa”, Jani virnistää loppuun.
DB Pro Services ja Visma Solutions yhteistyöhön Severan Power BI -rajapinnan toteuttamisesta.
Microsoftin Power BI on moderni ja tehokas datan analysointi- ja raportointiratkaisu, jonka avulla yrityksen kriittistä liiketoimintatietoa voidaan jalostaa, analysoida ja julkaista halutuille käyttäjäryhmille. Power BI:n avulla data saadaan visualisoitua helposti ymmärrettävään muotoon, kuten esimerkiksi dashboardeiksi niin, että loppukäyttäjiltä ei vaadita mitään business intelligence -ratkaisuiden osaamista. Power BI soveltuu sekä nopeaan ad-hoc tyyppiseen itsepalveluraportointiin että toistuvien raporttien tuottamiseen esim. päivä-, viikko- tai kuukausitasolla. Tuotetut raportit tai dashboardit voidaan julkaista käyttäjien nähtäväksi Power BI -desktoppiin, mobiilisovellukseen tai siten ne voidaan upottaa intranettiin tai office 365 -tuotteisiin kuten SharePoint, Teams tai Dynamics.
Visma Severa on asiantuntijayrityksille suunnattu projektinhallinta-järjestelmä, joka tuo CRM:n, projektien aikataulutuksen, resursoinnin, työajanseurannan sekä laskutuksen yhteen työkaluun. Severa kerää hajanaiset tiedot yhteen paikkaan ja kaikki työntekijät ovat saman työkalun äärellä. Severan avulla teet liiketoiminnan ohjaamisesta visuaalista, vaivatonta ja läpinäkyvää.
Visma Solutions ja DB Pro Services ovat sopineet yhteistyöstä, jolla Severan tietosisältö on helposti tuotavissa yrityksen Power BI -ratkaisuun datan jalostamista ja julkaisemista varten. DB Pro Servicen toteuttaman rajapinnan avulla tarvittava integraatio on toteutettavissa nopeasti verrattuna siihen, että sitä lähdettäisiin toteuttamaan yrityskohtaisesti. Ja mikäli Power BI ei ole yrityksellenne tuttu väline, tarvittaessa DB Pro Serviceltä on hankittavissa asiantuntija-apua niin datan muokkaamisen ja jalostamiseen kuin raporttien/dashboardien suunnitteluun ja toteuttamiseen.
Jos haluat kaiken hyödyn irti Severan sisältämästä liiketoimintatiedosta, niin lue lisää Visman sivuilta: https://psa.visma.fi/integraatiot/db-pro-services-power-bi/ tai ota yhteyttä DB Pro Servicen myyntiin, jani.savolainen@dbproservices.fi
Inkrementaalilataus Power BI Pro:ssa!
Käytettäessä Power BI:tä on ollut tähän asti yksi iso ongelma: Jos faktojen datamäärät ovat suuria, kestää raporttien päivittäminen aina kauan, koska koko datamassa pitää aina ladata sovellukseen uudestaan. Uuden Power BI version mukana tuli uusi ominaisuus, eli muutoslataukset. Tämä nopeuttaa sekä kehitystyötä, että ajastettujen latausten läpimenoaikoja, kun pelkät muutokset otetaan mukaan. Tästä on myös se hyöty, ettei yhteyttä tietolähteisiin tarvita pitää auki niin pitkään enää. Ja mikä hienointa, tämä ominaisuus on käytössä myös Power BI Pro-lisenssillä!
Käyttöönotto vaihe 1 – Power Query
Lisäävä päivitys otetaan käyttöön Power BI Desktop työkalun asetuksista.
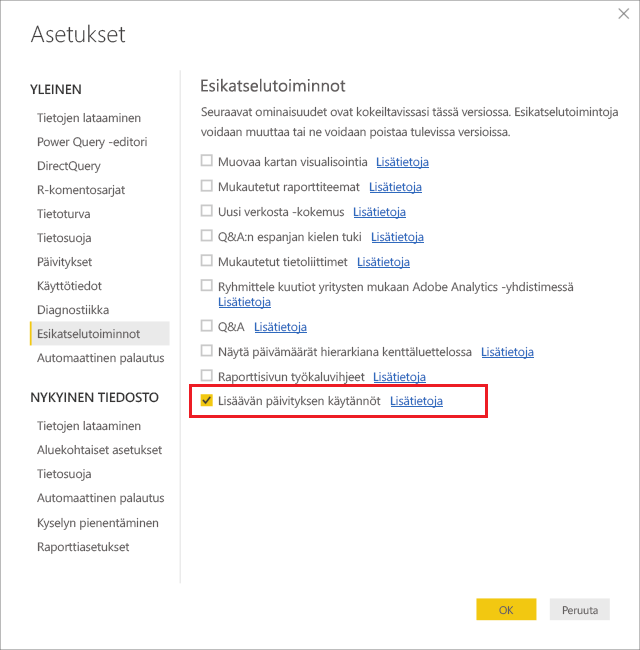
RangeStart– ja RangeEnd-parametrit luodaan Power Query editorista parametrien hallinta -kohdasta.
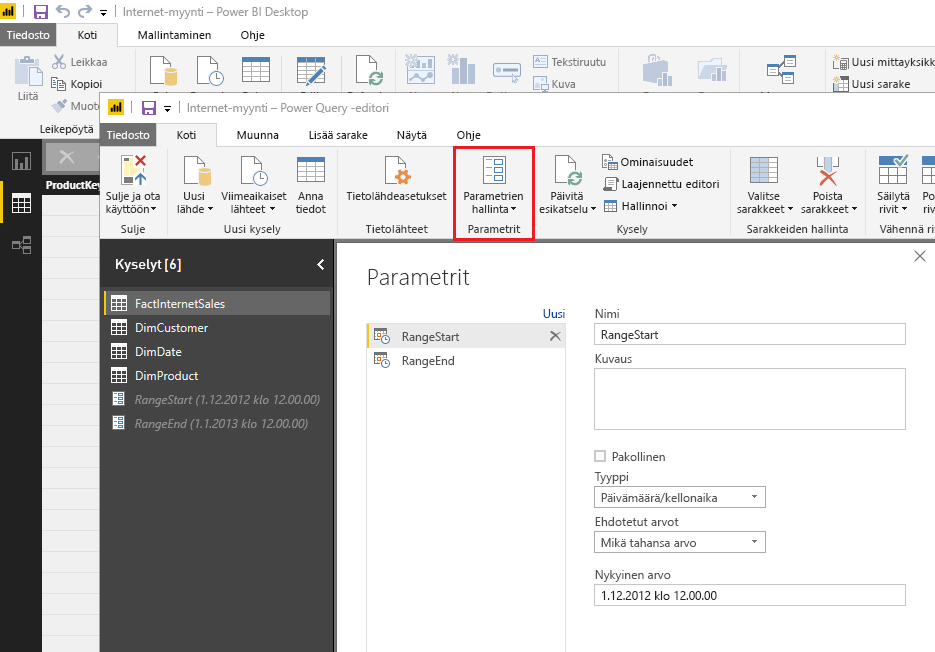
Nämä parametrien nimet ovat case-sensitiivisiä, koska ne ovat kiinteästi käytössä PBI algoritmiin koodattuna, ja PBI palvelussa niille ei enää tarvitse tehdä mitään. Eli ole tarkkana että kirjoitat parametrien nimet juuri oikeassa muodossa!
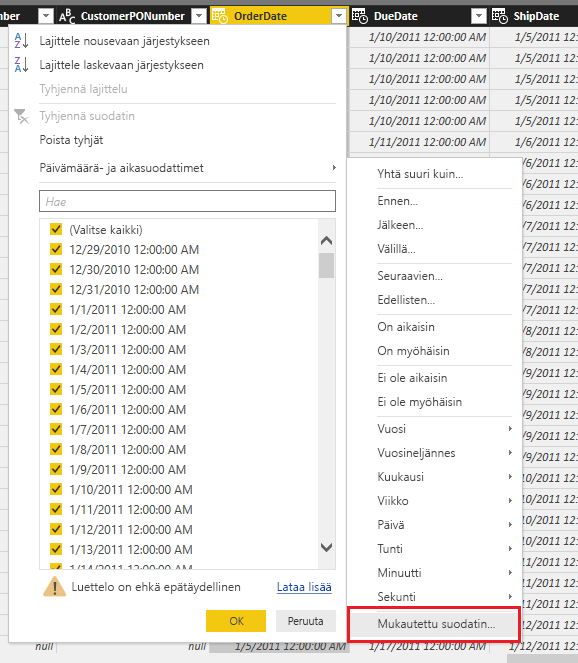
Kun parametrit on luotu voidaan ne ottaa käyttöön Power Query editorin päivämäärä sarakkeeseen määrittelemällä “mukautettu suodatin” kohdasta.
Käyttöönotto vaihe 2 – Datasetin asetukset ja julkaisu
Power BI desktopin raporttityötilassa ja sen KENTÄT -ikkunassa “Lisäävä päivitys” -kohta löytyy taulun pikavalikosta.
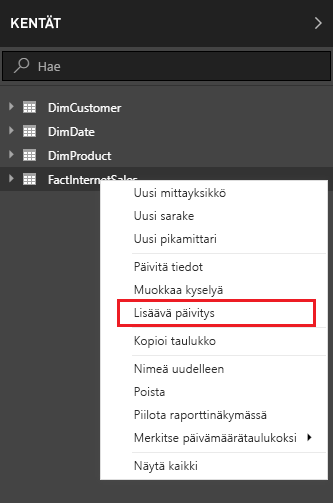
Jos Power Query:ssa ei ole tehty parametrejä oikein, tämä valinta ei ole käytettävissä. Seuraavassa näkymässä määritellään mm. datasetin koko sekä kuinka pitkältä ajalta data päivitetään.
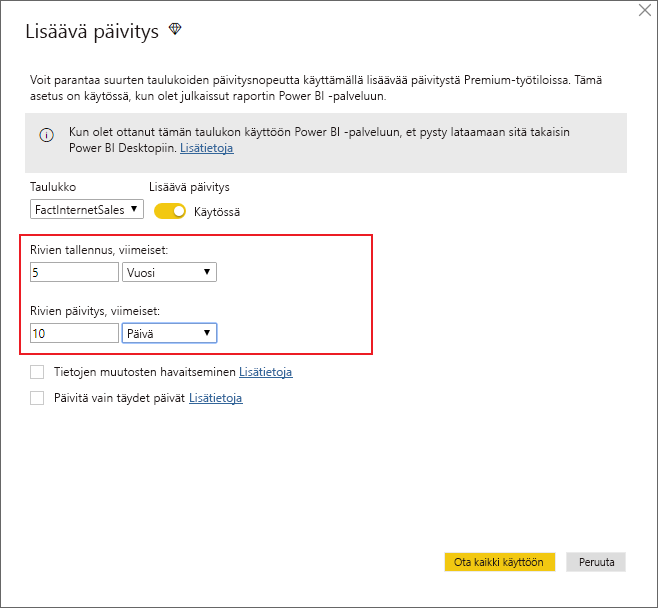
Ensimmäinen lataus kestää hieman kauemmin, koska lähdejärjestelmistä ladataan 5 vuoden historiatiedot ensimmäisen kerran. Tämä riittää Power BI Desktopin tiedoston asetuksista, seuraavaksi vain julkaisu verkon työtilaan ja “Lisäävä päivitys” on käytössä automaattisesti.
Rajoitukset
- Uuden ominaisuuden tuki perustuu lähdejärjestelmiin jotka osaavat käyttää SQL-syntaksia
- Muut lähteet, esimerkiksi BLOB, Excel, REST, CSV eivät toimi suoraan
- Inkrementaalilatauksen sisältävä PBIX tiedosto joka ladataan työtilasta kehityskoneelle ei ole enää muokattavissa. Tulevissa versiossa tämä pitäisi olla mahdollista.