SQL Server-tietokanta ja klassinen DataOps – Clean install ja SQL-tietokannan luonti

Tämä blogi jatkaa blogisarjaani SQL Server-tietokantojen klassiseen DataOpsiin liittyen. Tässä blogissa pureudutaan ns. Clean install -skriptin tekoon, eli kun softa asennetaan ensimmäisen kerran hermeettiseen ympäristöön. Kuten edellisessä blogissani aihetta sivusin, on tätä varten viisasta luoda muuttumaton skriptirunko, jossa tietokannan ns. corekomponentit asennetaan ja jäädytetään tähän versioon, jotta uusiin versioihin voidaan tehdä omat erilliset päivitysskriptinsä.
Clean install-skriptimoduulit
Clean install-skriptistä tulee helposti aika iso. Siinä missä pienelle, yksinkertaiselle tietokannalle voi riittää yksi skriptimoduuli ja tuhat koodiriviä, kannattaa hieman kompleksisempi tietokanta purkaa osiin. Tämä takaa ketterän ylläpidettävyyden ja lisää selkeyttä ja rakennetta skripteihisi ja toimii hyvänä pohjana tulevien versioiden ylläpitoskripteille. Tässä vielä kertauksen vuoksi Clean Install -skriptin mahdollinen jako moduuleihin. Moduuleita nimettäessä voi selkeyden vuoksi käyttää ajojärjestykseen liittyvää enumerointia. Tällainen rakenne mahdollistaa jopa kymmenien tuhansien koodirivien modulaarisen toteutuksen. Proseduurit ja funktiot voit pilkkoa kunkin omikse skripteikseen jos ne ovat kompleksisia ja niitä on todella paljon. Tämä lisää kokonaisuuden ylläpidettävyyttä.
Clean Install-skripteissä sinulla olisi hyvä olla vähintään:
- Core-skripti, jossa tietokannan (uudelleen-) luontiskriptit käyttäjyyksineen.
- Tables and views -skriptiin sijoitetaan taulut ja näkymät uudelleenluonteineen.
- Drop procedures -skripti (tai Drop Programmability) tiputtaa kaikki user stored proceduret ja käyttäjäfunktiot tietokannasta.
- Table types -skripti (uudelleen-)luo kaikki taulutyypit.
- Create procedures (tai Create Programmability) -skripti (uudelleen-)luo kaikki user stored procedure ja käyttäjäfunktiot.
- Encrypted procedures -skripti (uudelleen-)luo kaikki kryptatut user stored proceduret.
- Populate tables -skripti truncatoi ja populoi käyttäjätaulujen sisällön (=alustus).
- Jobs -skripti (uudelleen-)luo ratkaisun SQL Server jobit.
- Version -skripti hoitaa lopuksi versiopäivityksen lokitauluun.
SQLCMD -tila
SQL Server Management Studion (SSMS) SQLCMD-tila on erityinen suoritustila, jonka avulla voit suorittaa SQLCMD-komentoja ja T-SQL -kyselyitä SSMS:n Query Analyzerissä. Kun SQLCMD-tila on käytössä, voit sisällyttää komentosarjoihisi SQLCMD-kohtaisia komentoja, mikä mahdollistaa monimutkaisempia ja automatisoidumpia tehtäviä, kuten komentosarjojen suorittamisen useille palvelimille, muuttujien käyttämisen tai ulkoisten komentosarjojen suorittamisen tiedostoista. Edelleen, voit suorittaa näitä komentoja esim. Windows Installerista käsin, jolloin voit syöttää TSQL-asennusskripteillesi ympäristömuuttujien arvoja esimerkiksi promptaamalla, saaden näin skriptit konfiguroitaviksi ja dynaamisiksi.
Voit aktivoida SQLCMD-tilan SSMS:ssä Query-valikosta valitsemalla ”SQLCMD Mode”, mikäli haluat suorittaa tietokantaskriptejäsi ko. tilassa:
Ympäristömuuttujat määritellään “:setvar” -määreellä, esimerkiksi:
:setvar DBFilePrimaryPath “C:\Program Files\MyDB\SQLData\Data”
Edelleen, ympäristömuuttujaan voidaan viitata T-SQL-skriptissä seuraavasti:
$(DBFilePrimaryPath)
Core-skripti
Core-skriptiin on hyvä sijoittaa ainakin:
- Tietokannan (uudelleen-)luonti
- Tietokanta-asetukset
- Loginit
- Käyttäjät
- Roolit
- Käyttöoikeudet
- Kredentiaalit
- Proxyt
SQL Server-tietokannan (uudelleen-)luonti
Ohessa esimerkki käyttäjätietokannan (uudelleen-)luonnista:
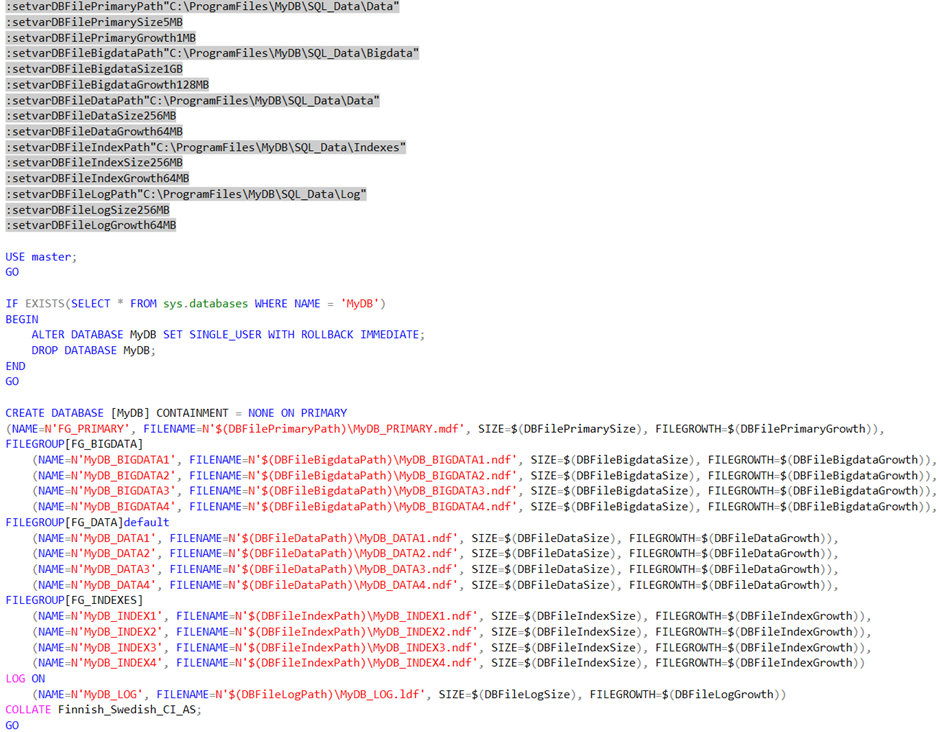
Huomaathan, että skriptissä on parametroitu muun muassa tiedostojen saantipolut, oletuskoko sekä kasvuvauhti tietyillä oletusarvoilla. Tällä tavalla käyttäjä voi asennuksen yhteydessä, esimerkiksi Windows installerin kautta vaikuttaa deployattavan tietokannan sijaintiin, kokoon sekä kasvuvauhtiin, jolloin ne saadaan heti konfiguroitua ympäristölle optimaalisiksi.
Koska skripti on uudelleenajettava, seuraavaksi skriptissä poistetaan mahdollisesti jo luotu tietokanta. Sitten luodaan tietokanta. Tämän jälkeen tulee tietokannan varsinainen luontiskripti, jossa on parhaana käytäntönä omat file grouppinsa big datalle, datalle sekä indekseille jaoteltuina kukin neljään datatiedostoon suorituskyvyn takaamiseksi.
Filegroupeista ja niiden luonnista sen verran, että SQL Serverin versiosta 2016 lähtien traceflag 1117:aa tietokantatasolla emuloiva AUTOGROW_ALL_FILES -optio kannattaa laittaa heti alkuun päälle: Tällöin, kun datatiedostoa kasvatetaan, kasvatetaan kaikkia tiedostoja samanaikaisesti, jotta ne pysyvät samankokoisina, mikä vähentää allokaation contentionia. Huom! Kyseisen määrityksen aikana kannassa ei saa olla kiinni muita käyttäjiä, joten sitä ei pysty enää tekemään onlinena, vaan se kannattaa laittaa heti päälle:
ALTER DATABASE [MyDatabase] MODIFY FILEGROUP [BIG_DATA] AUTOGROW_ALL_FILES
Tiedostokoot ja niiden kasvattaminen SQL Server-tietokannassa
Tämän lisäksi keskeisiä seikkoja ovat myös järkevät aloituskoot ja kasvuinkrementit loki- ja datatiedostoille, jotka riippuvat installaation koosta ja tiedostojen kasvuodotuksista. Tästä aiheesta voisikin kirjoittaa oman bloginsa, kuitenkin ohessa muutama keskeinen nosto: Nyrkkisääntö kasvunvaralle on noin 10 – 25% per inkrementti, mutta kuitenkin siten, että määrittellään kasvu magatavuina, ei prosentteina. Näin kasvu ei karkaa lapasesta ajan saatossa. Pienemmillä tietokannoilla voi olla sopivaa 64 – 256 MB kasvuinkrementti, kun taas suuremmilla se voi olla helposti jopa 1, 2, 4 GB tai enemmän.
Vakioitu tiedostokoon kasvu vähentää tiedostojen pirstoutumisen riskiä. Kun datatiedostot kasvavat pienin, tasaisin askelin, käyttöjärjestelmän on helpompi varata yhtenäistä levytilaa, mikä auttaa ylläpitämään hyvää I/O-suorituskykyä. Pirstoutuneet tiedostot voivat lisätä levyn I/O-toimintoja, mikä hidastaa tietokannan suorituskykyä. Tyypillisesti kannattaa myös laittaa instant file initialization -optio päälle (”perform volume maintenance tasks”). Se on SQL Serverin ominaisuus, joka mahdollistaa datatiedostojen merkittävästi nopeamman luomisen ja laajentamisen ohittamalla uuden levytilan nollaamisen. Tämä on erityisen tärkeää siksi, että SQL Server joutuu joka kerta odottamaan, kun sen datatiedosto kasvaa. Jos instant file initialization -optio ei ole päällä, se on SQL Serverin näkövinkkelistä vähän kuin katselisi robotin kävelyä mudassa.
Kun SQL Server luo tapahtumalokitiedoston tai kasvattaa sitä, se jakaa lokitiedoston pienempiin segmentteihin, joita kutsutaan virtuaalisiksi lokitiedostoiksi (vlf). SQL Server hallitsee näitä VLF-tiedostoja sisäisesti mahdollistaen tapahtumalokin tehokkaan käsittelyn. Luotujen VLF-tiedostojen määrä riippuu tapahtumalokitiedoston koosta ja niiden lisäysten koosta, joilla loki kasvaa. Lokitiedostoissa n. 1000 vlf:ää alkaa olla tyypillisesti SQL Serverin toimintaa hidastava määrä. Tämän takia ei kannata antaa lokitiedostolle alun alkaenkaan liian pientä tiedostokokoa.
Näin ollen, kuten arvata saattaa, olisikin suotavaa, että että data- ja lokitiedostojen autogrowtheja yritetään välttää viimeiseen asti. Se on aina hidastava tekijä, vaikka Instant File Initialization -oikeus olisi käytössä. Tiedostot kannattaakin jo alkuun määritellä täyttämään n. 80-prosenttisesti niille suunnitellut ja määritellyt levytilat, mikäli tämä vain suinkin on mahdollista.
Huom! Jos olet tekemässä tietokantaasi muulle kuin fyysiselle tai virtualisoidulle palvelimelle, preferenssit ovat esimerkiksi Azure PaaS-ratkaisussa (Managed Instance, SQL database) kovin erilaiset, eikä yllä oleva skripti ole näihin käyttötapauksiin sinällään käyttökelpoinen. Tässäkin olisi uuden blogin kirjoittamisen paikka.
Pari huomiota tietokantaoptioista
Tietokantaoptioista nostan pari tärkeää optiota ylitse muiden:
- SET AUTO_UPDATE_STATISTICS -optio kannattaa pitää päällä, mikäli haluat, että SQL Server päivittää automaattisesti indeksi- ja taulustatistiikkoja, kun ne happanevat. Prosessi lähtee käyntiin silloin, kun jokin kysely koskee vanhentuneisiin taulu- tai indeksistatistiikkoihin. (~>=20% muuttunutta dataa). Tämä johtaa yleensä tasaisempaan ympärivuorokautiseen suorituskykyyn kuin ilman tätä optiota, koska query optimizer kykenee tekemään järkevämpiä suoritussuunnitelmia. Kuitenkin esimerkiksi ympäristössä, jossa on SQL Serverin standard edition tai muutoin niin laajoja ja hardware-resurssien kannalta raskaita indeksi- ja statistiikkapäivityksiä, että ne halutaan ajoittaa aina palveluajan ulkopuolelle, ei tuolloin tätä optiota kannata pitää päällä laisinkaan.
- SET AUTO_UPDATE_STATISTICS_ASYNC -option ollessa päällä SQL Server sallii kyselyn suorittamisen samalla, kun sille tuoreutetaan statistiikkoja, mutta vain, jos myös SET AUTO_UPDATE_STATISTICS -optio on päällä. Tällöin SQL Serverin ei tarvitse odottaa tähän kyselyyn liittyvien statistiikkojen päivitystä, joka voi kestää joskus useita minuutteja, pahimmillaan jopa tunteja, vaan käyttää vanhaa, saatavilla olevaa statistiikkaa kyselyn suorittamiseen. Tätä optiota kannattaa siis soveltaa etenkin silloin, kun sinulla on isoja, herkästi muuttuvia tietokantatauluja, joihin kohdistuvissa kyselyissä on korkea vasteaikavaatimus.
Loppusanat
Muista kuitenkin, että vaikka kuinka yrittäisit ennakoida ja parametroida kaikki mahdolliset ympäristömuuttujat, on huolellinen integraatio- ja hyväksymistestaus kaiken A ja O. Silti, etenkin tuotteen ensimmäisissä versioissa, saattaa herkästi jäädä jotain oleellista tai yllättävää huomioimatta. Rapatessa roiskuu.
Haluatko kysyä jotakin SQL Server DataOpsiin tai tietokantoihin liittyen? Ole hyvä ja ota yhteyttä!

Jani K. Savolainen
jani.savolainen@dbproservices.fi
0440353637
VP & Chairman
DB Pro Services Oy


