Tietojenkäsittelytieteessä vain harvat ismit säilyvät vuosikymmeniä. Kuitenkin SQL-relaatiotietokantojen kohdalla näin on päässyt käymään. Tässä blogisarjassani käsittelen tietokantojen kehittymistä 1960-luvulta tähän päivään sekä pyrin hahmottelemaan tulevaisuutta. Blogisarjani ensimmäinen osa valottaa tietokantojen aamunkoittoa ja historiaa.
SQL-relaatiotietokantojen historia lähtee liikkeelle jo 1970-luvulta saakka. Tätä ennen on kuitenkin hyvä ymmärtää, mistä lähtökohdista päädyttiin relaatiotietokantoihin ja SQL:ään.
Tietokannan määritelmä
Tietojenkäsittelytieteessä tietokanta on ”järjestetty kokoelma tietoja tai tietovarastotyyppi, joka perustuu tietokannanhallintajärjestelmän (DBMS) käyttöön.” Toisin sanoen se on ohjelmisto, joka on vuorovaikutuksessa loppukäyttäjien, sovellusten ja itse tietokannan kanssa tietojen tallentamiseksi ja analysoimiseksi. Tietokannanhallintajärjestelmä kattaa lisäksi tietokannan hallinnointiin tarjotut keskeiset toiminnot. Tietokannan, tietokannanhallintajärjestelmän ja siihen liittyvien sovellusten kokonaisuutta voidaan kutsua tietokantajärjestelmäksi. Usein termiä ”tietokanta” käytetään myös löyhästi viittaamaan mihin tahansa DBMS:ään, tietokantajärjestelmään tai tietokantaan liittyvään sovellukseen.
Pieniä tietokantoja voidaan säilöä tiedostojärjestelmässä, siinä missä suuremmat tietokannat voivat vaatia alustakseen useamman palvelimen muodostaman klusterin tai pilvipohjaisen alustaratkaisun. Tietokantasuunnittelu yleisesti on yhdistelmä teoriaa sekä parhaita käytäntöjä, jossa tulee keskeisenä elementtinä on tietomallinnus. Tämän lisäksi tietokantaa suunniteltaessa tulee ottaa huomioon tehokas datan esitysmuoto ja tallennus, kyselykieli / -kielet, tietoturva ja yksityisyys sekä hajautetun tietojenkäsittelyn haasteet mukaan lukien jatkuva pääsy dataan sekä vikasietoisuus. Tietomallinnuksesta voit lukea lisää blogisarjastani Tietomallinnus – intro – DB Pro Services.
Terminologia
Tietokanta” viittaa yleisesti relationaaliseen dataan, joka on järjestetty tietokannanhallintajärjestelmässä siten, että käyttäjät pääsevät ohjelmallisesti käsiksi tähän dataan tai sen osajoukkoon, jotka sijaitsevat yhdessä tai useammassa tietokannassa.
Tietokannanhallinta voidaan jakaa neljään eri pääkategoriaan:
“Data definition”tarkoittaa datan organisoimiseen liittyviä luonti- muutos- ja poisto-operaatioita, eli suomeksi sanottuna itse tietorakenteiden hallinnan toimenpiteitä.
“Update” tarkoittaa varsinaisen datan lisäys- muutos- ja poisto-operaatioita olemassa olevien tietorakenteiden puitteissa.
“Retrieval” tarkoittaa tiedon tarjoamista tietokannasta eteenpäin prosessoitavaksi muille sovelluksille ymmärrettävässä muodossa. Data voi olla tallennettuna valmiiksi ymmärrettävässä muodossa, tai sitten sitä pitää implisiittisesti yhdistellä tai muokata ymmärrettävään muotoon.
“Administration” sisältää suuren määrän erilaisia tietokantojen hallintaan liittyviä tehtäviä, kuten tietokannanhallintajärjestelmien asennus ja konfigurointi, käyttäjätilien ja käyttöoikeuksien hallinta ja tietoturva, datan eheystarkistukset, jatkuvuudenhallinta sekä korkea käytettävyys, tietokantojen varmistus- palautustoimenpiteet, performanssidiagnostiikka, kapasiteettisuunnittelu jne.
Fyysisesti tietokantapalvelimet ovat dedikoituja palvelimia, joissa tietokannat käyttävät tietokannanhallintajärjestelmää ja siihen liittyviä ohjelmistoja. Tietokantapalvelimet ovat yleensä moniprosessorisia tietokoneita, joissa on runsaasti muistia ja RAID-levyryhmiä, joita käytetään tehokkaaseen tallennukseen.
Tietokannat voidaan luokitella kolmeen eri pääryhmään niiden sisältämän datan esitysmuodon (data format) perusteella:
- Strukturoitu
- Semistrukturoitu
- Strukturoimaton
Strukturoitu data perustuu staattiseen datan esitysmuotoon eli skeemaan, jolloin kaikella datalla on samat tietokentät ja ominaisuudet. Tällöin eri oliot esitellään kaksiulotteisina tietokantatauluina, joiden kentät kuvaavat olioiden eri ominaisuuksia ja yksittäiset rivit tyypillisesti kutakin oliota. Hyvä esimerkki tästä on tietovarastoinnissa paljon käytetty päivätaulu, jossa on tehokkuuden ja yksinkertaisuuden vuoksi valmiiksi laskettuna keskeisiä ominaisuuksia eri päivämäärille.
D_DATE:
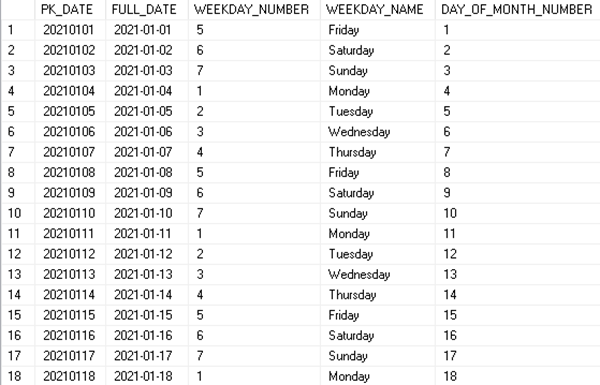
Strukturoitu data koostuu tyypillisesti relaatioista olioiden välillä, jotka ovat tyypillisesti luonteeltaan hierarkisia. Lue lisää relaatiomallista täältä: Tietomallinnus – Kolmas normaalimuoto (OLTP) – DB Pro Services.
Semistrukturoitu data on informaatiota, jolla on jonkinlainen struktuuri, mutta joka voi varioida oliokohtaisesti. Tästä hyvänä esimerkkinä toimii esimerkiksi henkilö, jolla voi olla yksi tai monta puhelinnumeroa, tai ei ollenkaan puhelinnumeroa. Tunnetuimpia semistrukturoidun datan esitysformaatteja on JSON (JavaSript Object Notation). Tässä esimerkki parista kontaktihenkilöstä CRM-tietokannassa:

Kaikki data ei ole strukturoitua tai edes puolirakenteista. Esimerkiksi kuvilla, ääni- ja videotiedoilla, dokumenteilla sekä binääritiedostoilla ei yleensä ole tiettyä rakennetta. Tällaista dataa kutsutaan strukturoimattomaksi dataksi.
Relaatiotietokannat
Toinen tapa luokitella tietokantoja on jakaa ne relationaalisiin ja ei-relationaalisiin tietokantoihin. Relaatiotietokantoja ovat sellaiset tietokannat, joissa säilötään ja kysellään strukturoitua dataa. Tällaista dataa ovat oliot, kuten esimerkiksi CRM-tietokannoissa yritykset, henkilöt ja tuotteet. Jokaisella oliolla on oma pääavaimensa (=”primary key”), joka identifioi olion muista saman taulun olioista. Tätä avainta käytetään viittauksissa tauluista toisiin (=viiteavain eli ”foreign key”).
Pää- ja viiteavainten käyttö mahdollistaa relaatiotietokannan normalisoinnin, mikä osittain tarkoittaa duplikaattien poistamista siten, että esimerkiksi yksittäisen asiakkaan tiedot tallennetaan kerran ja vain kerran, eikä erikseen jokaisen asiakkaan tilaamalle tuotteelle. Datan kyselyyn ja tallentamiseen käytetään SQL-kiletä (Structured Query Language), joka perustuu ANSI-standardiin, joka on sama useissa tietokantajärjestelmissä.
Ei-relationaaliset tietokannat
Ei-relationaaliset tietokannat ovat tiedonhallintajärjestelmiä, jotka eivät käytä relaatioskeemaa. Ei-relaatiotietokantoja kutsutaan usein NoSQL-tietokannoiksi, vaikka jotkut niistä tukevatkin SQL-kielen muunnelmaa. Näitä on neljää päätyyppiä:
- Avain-arvo -tietokannat (Key-value databases)
- Dokumenttitietokannat (Document databases)
- Kolumnaariset tietokannat (Column family databases)
- Graafitietokannat (Graph databases)
SQL-tietokantojen historia
SQL-tietokantojen historia lähtee liikkeelle 1960-luvulta, kun tietokoneiden prosessoriteho, muisti, tallennusmediat ja verkot tulivat pisteeseen, jolloin tietokantoja pystyttiin alkaa fyysisesti toteuttamaan. Tämän mahdollistivat lopullisesti 60-luvun puolivälissä kehitetyt tallennusjärjestelmät, kuten magneettilevyt, joiden käyttö yleistyi varsin nopeasti. Tätä ennen käytössä olivat sekventiaaliset magneettinauhat. Edelleen; tietokantateknologian kehittyminen voidaan jakaa kolmeen eri aikakauteen:
- Navigationaalinen aikakausi
- SQL/relationaalinen aikakausi
- Post-relationaalinen aikakausi
Kaksi tärkeintä varhaista navigointitietomallia olivat hierarkkinen malli ja CODASYL-malli (verkkomalli). Niille oli ominaista osoittimien (usein fyysisten levyosoitteiden) käyttö tietueiden välisten suhteiden seuraamiseksi.
Relaatiomallin esitteli Edgar F. Codd vuonna 1970. Tässä keskeisenä ajatuksena on etsiä dataa sisällön, eikä niinkään linkkien kautta. Kuitenkin, vasta 1980-luvulla tietokoneet alkoivat olla riittävän tehokkaita pyörittämään relaatiotietokantoja. Niistä tulikin hyvin suosittuja 1990-luvulla ja tänä päivänä ne ovat yhä käytetyimpiä SQL-tietokantatyyppejä. Näitä ovat mm. Microsoft SQL Server, IBM DB2, Oracle sekä MySQL.
1960-luku ja navigationaaliset tietokannat
Joskus 60-luvun puolivälissä “tietokanta” -termi alkoi vakiintua ensimmäisten direct-access-storagejärjestelmien myötä, mikä mahdollisti nauhapohjaisten järjestelmien päivittäisten eräajojen sijaan interaktiivisen käyttökokemuksen tietokoneiden kehittyessä tehokkaammiksi ja kyvykkäämmiksi. Tuohon aikaan Charles Bachman, IDS-tietokantatuotteen luoja, perusti Database Task Groupin CODASYL:in kanssa, joka standardoin COBOL-kielen. Vuonna 1971 markkinalle syntyi COBOL-pohjainen standardi, jonka ympärille versoi nopeasti monia tuotteita.
CODASYL-lähestymistapa tarjosi sovelluksille mahdollisuuden navigoida linkitetyssä tietojoukossa, joka muodostettiin suureksi verkoksi. Sovellukset saattoivat löytää tietueita jollakin kolmesta menetelmästä:
- Pääavaimen perusteella (ns. “CALC key”, joka luotiin tyypillisesti hashaamalla (HASH))
- Navigoimalla relaatioita pitkin (sets) tietueesta seuraavaan
- Skannaamalla kaikki tietueet sekventiaalisessa järjestyksessä (=alusta loppuun)
Myöhemmin järjestelmiin lisättiin ns. B-puita (B-tree), jotta voitiin tarjota tehokkaampia vaihtoehtoisia pääsypolkuja dataan. B-puuta voisi verrata puurakenteisesti navigoitavaan monitasoiseen puhelinluetteloon, jossa etsittävä data on järjestetty aakkosjärjestykseen ja siten merkittävästi nopeammin haettavissa kuin perinteisellä sekventiaalisella metodilla. Monet CODASYL-tietokannat lisäsivät loppukäyttäjiä varten myös ns. “deklaratiivisen kyselykielen”, joka oli erillään navigointisovellusliittymästä. CODASYL-tietokannat olivat kuitenkin monimutkaisia ja vaativat huomattavaa koulutusta ja vaivannäköä hyödyllisten sovellusten tuottamiseksi.
1970-luku oli SQL-relaatiotietokantojen lähtölaukaus
Edgar F. Codd työskenteli IBM:llä San Josessa, Kaliforniassa, yhdessä haarakonttorissa, joka oli pääasiassa mukana kiintolevyjärjestelmien kehittämisessä. Hän oli tyytymätön CODASYL-lähestymistavan navigointimalliin, erityisesti ”hakutoiminnon” puutteeseen. Vuonna 1970 hän kirjoitti useita artikkeleita, joissa esiteltiin uusi lähestymistapa tietokantojen rakentamiseen, joka lopulta huipentui uraauurtavaan tiedon relaatiomalliin suurille jaetuille “tietopankeille”.
Codd käytti matemaattisia termejä uuden mallinsa määrittämiseen: relaatiot (relation), monikot (tuples) ja toimialueet (domain) saivat korvata CODASYL:in taulukot, rivit ja sarakkeet. Codd kritisoikin myöhemmin käytännön toteutusten taipumusta poiketa mallin perustana olevista matemaattisista perusteista.
Hierarkkisissa ja verkkomalleissa tietueiden sisäinen rakenne sai olla hyvinkin monimutkainen. Esimerkiksi työntekijän palkkahistoria voitiin esittää ”toistuvana ryhmänä” työntekijätietueessa. Relaatiomallissa normalisointiprosessi johti siihen, että tällaiset sisäiset rakenteet korvattiin useissa taulukoissa pidetyillä tiedoilla, jotka yhdistettiin vain loogisten avainten avulla.
Sen lisäksi, että Codd tunnisti tietueet käyttämällä loogisia tunnisteita levyosoitteiden sijaan, hän muutti tapaa, jolla sovellukset kokosivat tietoja useista tietueista: Sen sijaan, että sovelluksia vaadittaisiin keräämään tietoja yksi tietue kerrallaan navigoimalla linkkejä, käytettiin deklaratiivista kyselykieltä. Kyselykielellä ilmaistiin, että mitä tietoja vaaditaan sen sijaan, että niitä pitäisi navigoida. Toisin sanoen; tehokkaan pääsypolun löytäminen tietoihin tuli tietokannan hallintajärjestelmän vastuulle sovellusohjelmoijan sijaan. Tätä prosessia, jossa kyselyt ilmaistiin matemaattisella logiikalla, alettiin kutsua kyselyoptimoinniksi.
Coddin paperin noteerasi kaksi ihmistä Berkeleystä, Eugene Wong ja Michael Stonebraker. He aloittivat INGRES-nimisen hankkeen käyttämällä rahoitusta, joka oli jo myönnetty maantieteelliseen opiskelijapohjaiseen tietokantaprojektiin sekä koodin tuottamiseen. Vuodesta 1973 alkaen INGRES toimitti ensimmäiset testituotteensa, jotka olivat yleisesti valmiita laajaan käyttöön vuonna 1979. INGRES oli samanlainen kuin System R useilla tavoilla, mukaan lukien ”kielen” käyttö tiedonhakuun, joka tunnetaan nimellä QUEL. Ajan myötä INGRES siirtyi yleistyvään SQL-standardiin.
Integroidut tietokannat
1970-80 -luvuilla pyrittiin suunnittelemaan tietokantoja myös tekemällä niille spesifiä rautaa ja sovelluskerrosta. Tavoitteena oli maksimoida performanssi matalilla kustannuksilla. Tällaisia kokonaisratkaisuja olivat mm. IBM:n System/38 sekä Teradatan ja Britton Leen “database machine”. Myös ICL kehitti ns. CAFS-kiihdyttimen, joka oli eräänlainen kovalevyn kontrolleri, jossa oli ohjelmoitava hakuominaisuus. Ongelmaksi näissä spesifeissä ratkaisuissa muodostui kuitenkin hidas jatkokehitettävyys verrattuna geneerisiin rautaratkaisuihin. Vaikka nykyisin suurin osa tietokannoista elääkin omaa elämäänsä geneerisen raudan rinnalla, silti esim. Netezza ja Oracle (Exadata) kehittävät edelleen tämäntyyppisiä tietokantaratkaisuja.
1970-luvun loppu ja SQL-tietokannat
IBM rupesi kehittämään System R:ää 1970-luvun alkupuolella ja se näki päivän valon 1974 ja -75 -taitteessa. Edistyksellistä System R:ssä oli, että data oli pilkottu useampaan tietueeseen siten, ettei sitä enää tarvinnut hakea yhdestä isosta “möhkäleestä”. Vuosina 1978 ja -79 testattiin tuotteen monikäyttäjäympäristöjä sekä standardoitiin SQL-kyselykieli. Toisin sanoen; Coddin ideat alkoivat saamaan tuulta alleen. Tämä johti IBM:n jatkokehittämään System R:stä tuotentokelpoisen SQL/DS:n, ja myöhemmin, laajemmin tunnetun Database 2:n (IBM DB2).
Larry Ellison astui kuvioihin Oracle-tietokannallaan vuonna 1978, joka perustui IBM:n System R:ään. Oracle V2 valmistui vuonna 1979.
Tällä välin Stonebraker otti oppia INGRES:istä ja kehitti uuden tietokannan, postgresin, joka tunnetaan nykyisin paremmin nimellä PostgreSQL. Postgresin päälle pystytään rakentamaan järeitä, korkean käytettävyyden globaaleja ratkaisuja ja se olikin vuonna 2023 eniten käytettyjä tietokantoja maailmassa yhdessä MySQL:n ja Microsoftin SQL Serverin kanssa.
1970-luvun puolivälissä kehitettiin myös MimerSQL-niminen tietokanta Uppsalan yliopistossa, mutta se konsolidoitiin yksityisyritykseen vuonna 1984. Toinen tietomalli, ns. ER-malli (entity-relationship model), kehitettiin vuonna 1976 ja se sai nopeasti suosiota. Sittemmin ER-malli istutettiin relaatiomalliin sopivaksi.
1980-luku ja desktop computing
Kun laskentateho kehittyi, 1980-luvulla kokeiltiin myös lähestymistapaa, jossa tietokannat olivat paikallisia, eli pyörivät clienteilla. Tästä käytettiin termiä “desktop computing”. Clientit käyttivät mm. taulukkolaskentaohjelmia, kuten Lotus 1-2-3:aa sekä ja tietokantasoftaa, kuten helppokäyttöiseksi suunniteltua dBASE:a, jonka luoja oli C. Wayne Ratliff. dBASE:sta tulikin 1980-luvun loppupuolen ja 1990-luvun alkupuolen välillä todellinen hittituote.
1990-luku ja olio-orientoituneisuus
1990-luvulla nostivat päätään objekti-orientoituneet tietokannat (object-oriented databases, “OO databases”). Tämä johtui pitkälti sovelluskehittäjien keskuudessa suosituksi nousseesta olio-ohjelmoinnista, jonka jatkeeksi tietokannat pyrittiin valjastamaan vaihtelevin tuloksin. Oliotietokantojen ideana on järjestää data olioiksi (object) ja niiden ominaisuuksiksi (attribute), sen sijaan, että normalisoitaisiin relaatiomallin kaltaisesti kaikki taulut. Tämä vaikuttaa tapaan käsitellä olioita sekä niiden välisiä suhteita. Hyvää tässä lähestymistavassa on yksinkertaisuus käyttäjän kannalta sekä se, että dataa voidaan kyselllä sille suunnitellulla spesifillä oliokielellä, joka on yksinkertaisempaa kuin perinteinen SQL. Huonoja puolia OO:ssa ovat kompromissit tietokannan suorituskyvyn suhteen. Olenkin vuosien varrella törmännyt useasti järeisiin OO-sovelluksiin, joiden tietokantapään suorituskyvyssä on ollut merkittäviä ongelmia.
2000-luku, NoSQL sekä NewSQL
2000-luku toi mukanaan XML-tietokannat, jotka ovat rakenteeltaan strukturoituja dokumenttitietokantoja. Näitä tietokantoja voidaan kysellä perustuen XML-dokumenttiattibuutteihin. Tällaiset tietokannat palvelevat parhaiten rakenteisia dokumenttikokoelmia, joiden esitysmuoto voi vaihdella säännönmukaseista fleksiibelimpään. Hyvänä esimerkkinä tästä ovat esimerkiksi patentit ja verotiedot.
NoSQL-tietokannat ovat tyypillisesti hyvin nopeita, eivät edellytä tiettyä tietokantaskeemaa ja niissä pyritään välttämään resurssiintensiivisiä JOIN-operaatioita denormalisoimalla dataa. Tällaiset tietokannat skaalautuvat horisontaalisesti.
Viime vuosina on ollut kysyntää massiivisesti hajautetuille tietokannoille, joilla on korkea partitiotoleranssi, mutta ns. CAP-teoreeman mukaan hajautetun järjestelmän on mahdotonta tarjota samanaikaisesti eheyden (consistency), saatavuuden (availability) ja osion (partition) toleranssia. Hajautettu järjestelmä voi täyttää minkä tahansa kaksi näistä takeista samanaikaisesti, mutta ei kaikkia kolmea. Tästä syystä monet NoSQL-tietokannat käyttävät ns. lopullista eheyttä (eventual consistency) tarjotakseen sekä saatavuus- että osiotoleranssitakuut heikentyneellä tietojen eheydellä.
NewSQL on nykyaikaisten relaatiotietokantojen arkkityyppi, jonka tavoitteena on tarjota sama skaalautuva suorituskyky kuin NoSQL-järjestelmät tarjoavat OLTP-työkuormiin, kuitenkin edelleen käyttäen SQL:ää säilyttäen näin olleen perinteisen tietokantajärjestelmän ACID-takuut (atomicity, consistency, isolation, durability).
Seuraavassa blogipostauksessani kuvailen tietokantojen nykytilaa.

Jani K. Savolainen
jani.savolainen@dbproservices.fi
0440353637
VP & Chairman
DB Pro Services Oy