Tämä postaus jatkaa blogisarjaani tietomallintamisesta (Tietomallinnus – Osa 1: Intro). Alla linkit muihin tietomallinnuksen blogisarjan blogeihin.
- Tietomallinnus – Osa 1: Intro
- Tietomallinnus – Osa 2: Kolmas normaalimuoto (OLTP)
- Tietomallinnus – Osa 3: Tähtimalli (Star schema)
- Tietomallinnus – Osa 4: Lumihiutalemalli (Snowflake schema)
- Tietomallinnus – Osa 5: Enterprise Data Warehouse BUS
- Tietomallinnus – Osa 6: Data Vault
OLTP-tietomallin hyödyt
OLTP-tietomallinnuksesta on monia hyötyjä, jotka voivat parantaa liiketoiminnan tehokkuutta ja päätöksentekoa. Tässä ovat keskeisimmät hyödyt:
Parannettu suorituskyky ja tehokkuus: Hyvin suunniteltu OLTP-tietomalli minimoi tietokannan viiveet ja maksimoi suorituskyvyn tarjoamalla nopeat luku- ja kirjoitusoperaatiot. Tämä on erityisen tärkeää transaktiointensiivisille sovelluksille, joissa nopea datan käsittely on kriittistä.
Tietojen eheys ja luotettavuus: Normalisointiprosessin kautta tietokannan tietojen toisteisuus vähenee ja tietojen eheys paranee. Kun tieto tallennetaan vain kerran, päivitysten, lisäysten ja poistojen yhteydessä virheiden riski pienenee, mikä lisää tietokannan luotettavuutta.
Vähemmän lukitustilanteita ja rinnakkaisuuden hallintaa: OLTP-tietomallit on suunniteltu minimoimaan lukitustilanteet ja parantamaan rinnakkaisuuden hallintaa, mikä on tärkeää suurissa ja monimutkaisissa järjestelmissä, joissa useat käyttäjät suorittavat transaktioita samanaikaisesti.
Skaalautuvuus: Tehokkaan tietomallinnuksen ansiosta OLTP-järjestelmiä on helpompi skaalata vastaamaan liiketoiminnan kasvua. Kun tietokannan rakenne on suunniteltu huolellisesti, järjestelmä voi käsitellä suurempia tietomääriä ja lisääntyviä käyttäjämääriä ilman suorituskyvyn merkittävää heikkenemistä.
Parempi päätöksenteko: Vaikka OLTP-tietokannat eivät suoraan sovellu raportointiin ja analytiikkaan, niiden keräämä ajan tasalla oleva ja luotettava data on arvokasta tietoa päätöksenteolle. Tehokkaan datan keräämisen ja hallinnan ansiosta organisaatiot voivat tehdä tietoon perustuvia päätöksiä nopeammin.
Kustannussäästöt: Tehokas tietomallinnus voi vähentää tarvetta jatkuvasti investoida lisäresursseihin, kuten lisämuistiin tai tehokkaampiin prosessoreihin, suorituskyvyn ylläpitämiseksi. Tämä voi johtaa merkittäviin säästöihin pitkällä aikavälillä. Edelleen, mitä tehokkaampi OLTP-tietokanta-alusta on, sitä suuremmat ovat myös sen generoimat lisenssisäästöt on-premises-ympäristössä ja kapasiteettipohjaisen laskutuksen säästöt julkipilvessä.
Ylläpidon ja kehityksen helpottuminen: Selkeä ja hyvin suunniteltu tietomalli helpottaa ylläpitoa ja uusien toiminnallisuuksien kehittämistä. Kun tietomalli on järjestelmällinen ja looginen, kehittäjien on helpompi ymmärtää ja tehdä muutoksia järjestelmään.
Näin ollen, OLTP-tietomallinnuksen hyödyt ulottuvat operatiivisen tehokkuuden parantamisesta aina strategisen päätöksenteon tukemiseen, mikä tekee siitä kriittisen osan nykyaikaista liiketoimintaa.
Miksi OLTP-tietomallinnus?
Operatiiviset eli ns. OLTP-tietokannat ovat transaktiointensiivisiä. Tämä tarkoittaa, että dataa kirjoitetaan ja päivitetään tietokantaan tiuhaan tahtiin lukuoperaatioiden lisäksi, usein 60/40 – 90/10 RW-suhteessa. Tällaisia ovat mm. ERP-tietokannat. OLTP-työkuormille tyypillisiä piirteitä ovat pienet tulosjoukot sekä yksinkertaiset kyselyt. Edelleen; OLTP-työkuormat ovat luonteeltaan satunnaisista luku- ja kirjoitusoperaatioista koostuvia, joissa on pienempi tallennusblokkikoko kuin tietovarastojärjestelmissä. OLTP-työkuormille on tyypillistä myös latenssiherkkyys.
Kaikki tämä asettaa erityisiä vaatimuksia tietomallille, jotta tietokannanhallintajärjestelmän suorituskyky ja skaalautuvuus ei muodostu pullonkaulaksi, kun sen työkuormat ja käyttäjämäärät lisääntyvät. Tämän takia hyvä OLTP-tietomalli onkin varsin polarisoitunut verrattuna hyvään tähtimalliin (tietovarasointi). Hyvä OLTP-tietomalli onkin summeerattuna sellainen, jossa oliot ja niiden ominaisuudet esitetään kerran ja vain kerran, relaatioineen. Täten saadaan tietokannan transaktionaalinen suorituskyky maksimoitua ja mahdolliset lukitustilanteet minimoitua.
Mihin OLTP-tietokanta ei sovellu
Koska operatiivisen tietokannan tietomalli on optimoitu transaktionaaliseen dataan, on siitä usein hidasta ja monimutkaista kysellä suuria tietomääriä. Juuri tästä syystä OLTP-kannat eivät sovellu hyvin raportointiin, koska raportoinnissa on tyypillistä yhdistellä, summata ja jalostaa suuria datamääriä keskenään. Kaikki tämä johtaa OLTP-kannassa helposti korkeaan prosessorin käyttöasteeseen, muistiongelmiin sekä hallitsemattomiin levykuormiin ja lukitustilanteisiin.
Tyypillinen raportoinnin evoluutio tällaisissa tietokannoissa on ns. ”laastariratkaisu”, eli ensin tehdään erillisiä raportointitauluja tai muistinvaraisia tauluja OLTP-kantaan. Sitten kun tämä ei enää riitä, aletaan replikoida reaaliaikaisesti dataa kantakopioon, joka on tarkoitettu vain kyselykäyttöön. Kaikki tämä johtaa kuitenkiin hitaaseen, kompleksiseen, virhealttiiseen ja siiloutuneeseen raportointiin. Viimeistään tässä vaiheessa onkin järkevää mallintaa erillinen datamart tai konsernitietovarasto (EDW), joka on tietomalliltaan optimoitu suurien tietomäärien pitkäkestoiseen varastointiin ja suoraviivaiseen raportointiin. Tietovarastomallinnuksen menetelmistä ja parhaista käytännöistä kerron lisää tulevissa blogipostauksissani.
Tietokannan normalisointi
Tietokannan normalisointi on systemaattinen metodi, joka tähtää maksimaaliseen tiedon saatavuuteen ja tallennuksen eheyteen. Metodia seuraamalla voidaan kehittää tehokkaita operatiivisia tietokantoja. Normalisoinnin ideana on asteittain pienentää tiedon toisteisuutta eli redundanssia sekä parantaa tietomallin eheyttä. Nyrkkisääntönä voidaan pitää, että:
- Kukin tieto on esitetty vain yhdessä paikassa
- Relaatiossa voi esiintyä vain siihen kuuluvaa dataa
- Päivitys kohdistuu vain yhteen paikkaan kerrallaan
Normalisointi tarkoittaa käytännössä tietokantataulujen (=oliot ja niiden ominaisuudet sekä relaatiot) järjestämistä tietyllä tavalla. Tauluja voidaan tarpeen mukaan luoda uusia ja niiden välillä voidaan siirtää attribuutteja. Alkuperäisenä normaalimuotojen kehittäjänä tunnetaan herra nimeltään Edgar F. Codd.
Ensimmäinen normaalimuoto (1NF)
Ensimmäinen normaalimuoto esittää, että tietokannan jokaisen sarakkeen arvot ovat atomisia. Normalisointi toteutuu pilkkomalla moniarvoiset attribuutit omiin tauluihinsa. Otetaan hauska esimerkki. Meillä on viulisteja, jotka omistavat on kukin yhdestä moneen stradivariusta:

Tämä tulisi jakaa kahteen erilliseen tauluun:
- Muusikoiden tiedot
- Stradivariukset

Toinen normaalimuoto (2NF)
Määritelmän mukaisesti; toinen normaalimuoto kieltää muiden kuin avainattribuuttien ei-triviaalit toiminnalliset riippuvuudet avainehdokkaan osaan.
- Jos jokaisen taulun avain koostuu vain yhdestä attribuutista, tietokanta on toisen normaalimuodon mukainen.
- Jos kantaan kuuluu tauluja, joiden avainkandidaatti koostuu useasta eri attribuutista (=komposiittiavain), ei mikään attribuutti, joka ei ole avain, saa olla osittain toiminnnallisesti riippuva mistään avainehdokkaasta.
- Jos attribuutti on riippuvainen koko avaimesta, eikä pelkästään osa-avaimesta, se saa sijaita taulussa toisen normaalimuodon mukaan.
Esimerkki. Stradivarius -taulussa on komposiittiavain eli ehdokasavain (Stradivarius, valmistusmaa). Taulu ei siis ole 2NF-muodossa:
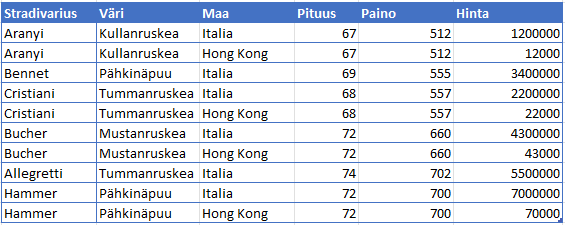
Kaikki kentät, jotka eivät ole riippuvaisia komposiittiavaimesta (pituus, paino), riippuvat Stradivarius-kentästä, mutta ainoastaan hinta riippuu myös valmistusmaasta. Tämä taulu voidaan muuttaa toiseen normaalimuotoon tekemällä Stradivariuksesta ehdokasavain, jotta jokainen ei-ehdokasavainmäärite riippuu koko ehdokasavaimesta, sekä poistamalla hinta erilliseen taulukkoon, jotta sen riippuvuus Valmistusmaasta voidaan säilyttää:
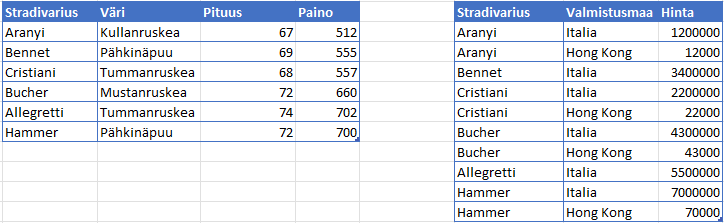
Kolmas normaalimuoto (3NF)
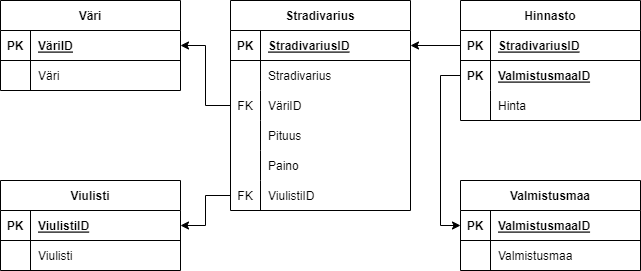
Kolmas normaalimuoto kieltää nbiiltä attribuuteilta, jotka eivät ole avaimia, “ei-triviaalit funktionaaliset riippuvuudet” muihin kuin avainehdokkaiden ylijoukkoon (=superset). Esimerkkitapauksessamme; Stradivarius-taululla on edelleen ei-triviaali funktionaalinen riippuvuus (väri on riippuvainen Stradivariuksesta). Siksi skeema ei ole 3NF:ssä, joten ei-triviaalit funktionaaliset riippuvuudet poistetaan sijoittamalla väri omaan tauluunsa sekä valmistusmaa omaan tauluunsa, johon viitataan hinnastotaulusta, ja lopuksi vielä lisätään puuttunut relaatio Viulistin ja Stradivariuksen väliltä:
Yhteenveto
Normaalimuotoja on kaikkiaan 6NF saakka. Kuitenkin OLTP-mallintamisessa harvoin tarvitaan edes neljättä normaalimuotoa.
Tarvitseeko organisaatiosi apua OLTP-tietokannan mallintamisessa? Ota yhteyttä allekirjoittaneeseen niin jutellaan lisää!
Jani K. Savolainen
jani.savolainen@dbproservices.fi
0440353637
VP & Chairman
DB Pro Services Oy