Tämä kirjoitus jatkaa blogisarjaani tietomallintamisesta. Edellisessä blogipostauksessani käsittelin kolmatta normaalimuotoa. (Tietomallinnus – Osa 2: Kolmas normaalimuoto (OLTP)). Tänään puhutaan tähtimallista (=star schema). Alla linkit muihin tietomallinnuksen blogisarjan blogeihin.
- Tietomallinnus – Osa 1: Intro
- Tietomallinnus – Osa 2: Kolmas normaalimuoto (OLTP)
- Tietomallinnus – Osa 3: Tähtimalli (Star schema)
- Tietomallinnus – Osa 4: Lumihiutalemalli (Snowflake schema)
- Tietomallinnus – Osa 5: Enterprise Data Warehouse BUS
- Tietomallinnus – Osa 6: Data Vault
Tähtimallin (star schema) hyödyt
Tähtimalli (star schema) on tietokantojen mallinnustapa, joka on erityisen hyödyllinen tietovarastoissa ja tietokanta-analytiikassa. Tässä on muutamia keskeisiä hyötyjä tähtimallin käytöstä:
1. Yksinkertaisuus ja helppolukuisuus
- Käyttäjäystävällinen rakenne: Tähtimallin selkeä ja yksinkertainen rakenne tekee siitä helppolukuisen ja ymmärrettävän sekä teknisille että liiketoiminnan käyttäjille.
- Yksinkertaiset kyselyt: Tähtimallin yksinkertainen rakenne mahdollistaa suoraviivaiset ja tehokkaat SQL-kyselyt, mikä helpottaa tietojen hakemista ja analysointia.
2. Tehokas kyselyjen suorituskyky
- Parannettu suorituskyky: Tähtimalli on optimoitu tietojen nopeaan hakemiseen, koska se vähentää monimutkaisten liittymien (joins) tarvetta verrattuna muihin malleihin, kuten lumihiutalemalliin (snowflake schema).
- Indeksointi: Dimension taulut voivat hyödyntää tehokasta indeksointia, mikä parantaa kyselyjen suorituskykyä.
3. Joustavuus ja laajennettavuus
- Laajennettavuus: Tähtimalli on helposti laajennettavissa uusilla dimensioilla ja tosiasioilla ilman suuria muutoksia olemassa oleviin tauluihin tai kyselyihin.
- Käyttö tapauksiin soveltuvuus: Tähtimalli sopii hyvin moniin liiketoiminnan tarpeisiin, erityisesti silloin, kun analysoidaan suuria tietomääriä ja tarvitaan nopeita vastauksia ad-hoc-kyselyihin.
4. Ylläpidon helppous
- Yksinkertainen ylläpito: Tähtimallin yksinkertainen rakenne tekee sen ylläpidosta helppoa. Muutokset dimensioihin ja tosiasioihin voidaan tehdä ilman suuria vaikutuksia muihin osiin tietovarastoa.
- Selkeä rakenne: Selkeä ja looginen rakenne helpottaa tietovaraston hallintaa ja tukee paremmin tietojen eheyttä ja laatua.
5. Tiedon monimuotoisuuden hallinta
- Moniulotteinen analyysi: Tähtimalli mahdollistaa moniulotteisen analyysin käyttämällä erilaisia dimensioita (esim. aika, paikka, tuote), mikä tekee siitä erinomaisen valinnan liiketoiminta-analytiikkaan ja raportointiin.
- Käyttäjäkeskeisyys: Tähtimallin käyttö mahdollistaa liiketoimintakäyttäjille suunnattujen raporttien ja kyselyjen suunnittelun heidän tarpeidensa mukaisesti, koska tiedot ovat helposti saatavilla ja analysoitavissa.
Miksi tähtimalli (star schema)
Yhteenvetona tähtimalli tarjoaa yksinkertaisen, tehokkaan ja joustavan tavan tietojen mallintamiseen ja hakemiseen tietovarastoissa, mikä parantaa sekä suorituskykyä että käytettävyyttä. Tämä tekee siitä suositun valinnan monissa liiketoiminnan analytiikkasovelluksissa.
Eräs fyysisten tietomallien tyypeistä on ns. tähtimalli. Se on raportointitietokannoissa (data mart, EDW) yleisimmin käytetty tietomalli. Tähtimalli on myös OLAP-teknologiassa käytetty skeema ja sitä käytetään hyvin yleisesti myös Power BI-raportoinnissa. Tähtimallin skeema sijoitetaan lähes poikkeuksetta omaan tietokantaansa sen intensiivisten lataus- / tietokantakyselykuormien takia, jotka poikkeavat merkittävästi perinteisten OLTP-kantojen työkuormatyypeistä (vrt. OLTP:n purskeiset vs. DW:n sekventiaaliset työkuormat). Vaikka tähtimallilla onkin tyypillisesti helppoa ja nopeaa mallintaa DW-tietokanta, ei sekään automaattisesti sovellu kaikkiin DW-käyttötapauksiin parhaalla mahdollisella tavalla.
Itse sain ensi puraisuni tähtimallista jo 90-luvun loppupuolella. Tämän jälkeen olen ehtinyt suunnitella ja toteuttaa vuosien varrella useita kymmeniä tähtimallisia tietokantoja moniin eri käyttötarkoituksiin.
Esimerkkicase
Esimerkkiasiakkaamme, kuvitteellinen B2C-yritys myy globaalisti yksityishenkilöasiakkailleen erilaisia tuotteita. Tuotteita voi ostaa kerralla useamman kappaleen ja niillä on aina kunakin ajanhetkenä tietty yksikkö- sekä näin ollen kokonaismyyntihinta. Asiakkaallamme on tarve tuottaa monipuolisesti raportteja sekä hyödyntää edistynyttä analytiikkaa erillisestä raportointikannasta ilman, että tuotantopalvelimen CRM-kanta häiriintyy (CPU-kuorma, levylatenssit, muistinkäyttö, lukitukset jne.). Ratkaisuksi tähän luodaan tähtimallinen data mart -tietokanta, johon tiedot ladataan operatiivisesta tietokannasta yöllisinä eräajoina.
Esimerkkimme tähtimallista.
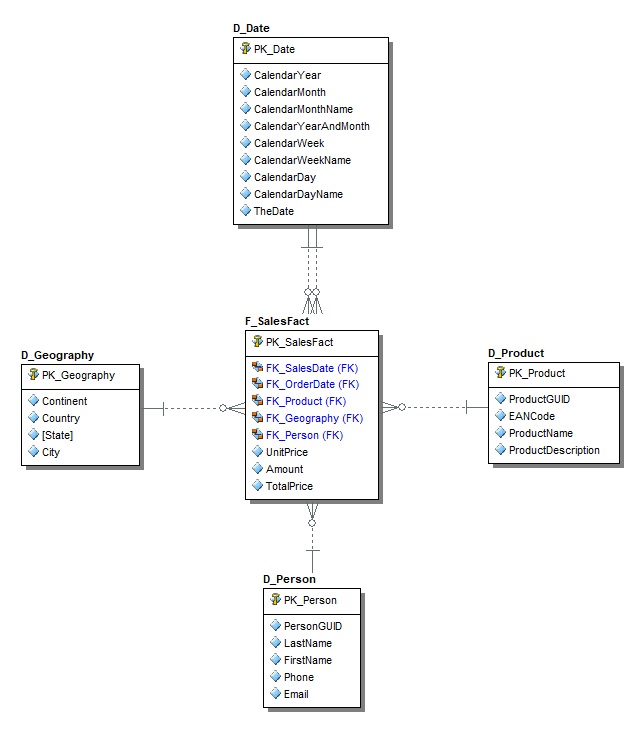
Tähtimallin taulut
Tähtimallissa on periaatteessa vain kahdenlaisia tauluja: Faktatauluja sekä niitä ympäröiviä dimensiotauluja. Sen normalisointi toteutetaan toisessa normaalimuodossa (2NF), jolloin sama tieto toistuu (=redundanssi) useamman kerran tietokannassa. Tällä tekniikalla saavutetaan kuitenkin merkittäviä helppokäyttöisyys- ja suorituskykyhyötyjä luotaessa erilaisia raportteja sekä analyysejä historiatyyppisestä datasta. Kuinka temppu sitten käytännössä tehdään?
Faktat ja dimensiot
Faktataulu sisältää tapahtumamuotoista tietoa, eli laskennallisia suureita, sekä niiden viittaukset tapahtumia kuvaaviin olioihin (dimensiot) sekä dimensioattribuutteihin. Jokaisesta faktataulun tapahtumasta (=transaction) on viittaukset sitä ympäröiviin dimensiotauluihin. Tätä voidaan ajatella siten, että jokaisen “tähden” ytimenä toimii faktataulu ja dimensiot ovat tähteä ympäröiviä sakaroita. Edelleen huomataan, että faktataulu sisältää avaimien lisäksi ainoastaan laskennallisia, aggregoitavia tietojäseniä eli mittaritietoa (=measure). Tarvittaessa faktataulun suorituskykyä voi parantaa lisäämällä sinne erilaisia laskennallisia kolumneja (=calculated members), jotka summautuvat eri tasoilla dimensioiden suhteen. Mitä nämä dimensiot sitten ovat?
Dimensionaalisissa tauluissa kuvataan kunkin faktarivin ominaisuuksia halutulla tiedon tarkkuustasolla. Eli esimerkiksi sitä, mikä oli tuotteen myyntipäivä tai että kuka ja mistä osti tietyn tuotteen. Kaikki dimensioattribuutit on jalostettu helposti ymmärrettävään muotoon ja NULL-arvot korvataan ns. ”undefined” -referensseillä eli default-arvoilla jotka kuvaavat sitä, että kentälle ei ole määritelty arvoa lainkaan, jotta turhalta kolmikantalogiikalta vältytään raportoinnin yhteydessä. Kirjainlyhenteiden ja koodien lisäksi monissa attribuuteissa käytetään luonnollista kieltä, jolloin datamassa muodostuu informatiivisemmaksi sekä helpommaksi raportoida ja analysoida. Tämän lisäksi on tyypillistä, että yksittäisistä dimensiojäsenistä (=dimension members) päätellään erilaisia ryhmitteleviä tekijöitä, kuten vaikkapa yrityksen liikevaihtoluokka. Operatiiviset e. luonnolliset avaimet (=natural key) kuljetetaan massalatausten (=ETL, ELT) mukana dimensiotauluihin omiksi kentikseen.
Tähtimallin avaimet
Tähtimallille ominaista ovat inkrementaaliset kokonaislukuavaimet eli nk. surrogaattiavaimet (=surrogate keys), jolloin skeeman suorituskyky on mahdollisimman hyvä. SQL Server -maailmassa kannattaa lähtökohtaisesti käyttää bigint -tietotyyppiä taulujen pääavaimille (=primary key) silloin, kun on odotettavissa, että kantaan tullaan hilloamaan vähintään miljardeja tietueita. Lisäksi annan pienen näppärän vinkin päivädimension pääavaimen luomiseen: Siihen kannattaa sijoittaa suoraan päivämäärä muodossa YYYYMMDD. Tämä mahdollistaa mm. sen, että faktataulun viiteavaimesta näkee suoraan, mille ajanjaksolle faktatieto sijoittuu.
Tähtimallin nimeämiskäytännöistä
Käytännön syistä on hyödyllistä nimetä fakta- ja dimensiotaulut aina siten, että niiden tyyppi voidaan tunnistaa kirjoitusasunsa perusteella. Itse pidän käytännöstä, jossa nimetään faktataulut “F_” -prefiksillä ja tarpeen tullen “Fact” -postfiksillä sekä dimensiotaulut “D_” -prefiksillä. Tämä mahdollistaa tunnistettavuuden lisäksi myös tietokantaympäristössä erilaisten skriptiautomaatioiden luonnin helpottumisen. Pääavaimet kannattaa nimetä selkeyden vuoksi “PK_” ja viiteavaimet (=referential key) “FK_”.
Tähtimallin granulariteetti
Faktataulun dimensioreferenssit käytännössä määrittelevät yhdessä tiedon esitystarkkuuden (=granularity). Tätä tarkkuustasoa ei voi myöhemmin enää tarkentaa rikkomatta koko dimensionaalista mallia, refaktoroimalla sitä ja tekemällä ETL-latauksia kokonaan uudelleen. Tämän vuoksi onkin tärkeää, että ensimmäinen mietitty asia per yksittäinen tähtimallin skeema (=fakta + dimensiot) on juurikin sen granulariteetti: Esimerkin data marttiimme onkin päätetty kerätä CRM-kannasta tuotemyyntien tapahtumatietoa päivätasolla, tuotteittain, henkilöittäin sekä kohdekaupungeittain. Jos esimerkiksi haluaisimme tietää jälkeenpäin tunnin tarkkuudella, että mihin aikaan jotain tiettyä tuotetta on tilattu, emme saisi tätä tietoa raportoitua data martin kautta, koska granulariteetti aikadimension suhteen on päivä (D_Date).
Faktataulun summautuvuus (=additivity)
Faktataulun kukin mitta-arvo voi summautua eri tavoin. Näitä on kolmea eri tyyppiä. Ne ovat:
– Non-additive measures. Tällaisia ovat sellaiset mitta-arvot, jotka eivät aggregoidu millään dimensiotasolla.
– Semi-additive measures. Tällaisia ovat sellaiset mitta-arvot, jotka aggregoituvat oikein vain tietyillä dimensiotasoilla.
– Full-additive measures. Tällaisia ovat sellaiset mitta-arvot, jotka aggregoituvat oikein kaikkien dimensiotasojen suhteen.
Aikadimensio ja dimensiohierarkiat
Aikadimensio sisältää hierarkkisen (=dimension hierarchy) kuvauksen kuhunkin faktataulun tapahtumaan liittyvästä ajankohdasta, esimerkiksi vuosi-kuukausi-päivämäärä. Esimerkissämme on jokseenkin kattava aikadimensio, mutta perusteellisissa aikasarja-aritmetiikkaa vaativissa ympäristöissä saattaa olla tarvetta jopa kymmenille hierarkian tasoille (=level). Myös rinnakkaisia hierarkioita voi olla useita, esim. vuosi-kuukausi-päivämäärä vs. vuosi-kvartaali-kuukausi. Aikadimension generointi kannattaa automatisoida erillisellä skriptillä, jolloin sen ylläpitäminen on vaivatonta.
Role playing -dimensiot
Tähtimallille ominaista on dimensiotaulujen monikäyttöisyys. Ajatellaanpa vaikkapa aikadimensiota (D_Date). Voimme haluta seurata tuotteen myyntiä esimerkiksi sekä myyntipäivän (FK_SalesDate), että tilauspäivän (FK_OrderDate) suhteen. Tämä on mahdollista luomalla yksinkertaisesti kullekin tällaiselle tarpeelle oma viiteavaimensa faktatauluun, joka sitten viittaa samaan dimensioon mutta mahdollisesti eri riviin kyseisessä taulussa. Esimerkiksi siten, että FK_OrderDate viittaa tilauspäivämäärätietueeseen ’18.6.2023’ aikadimensiossa (D_Date) ja FK_SalesDate viittaa vastaavasti tuotteen myyntipäivämäärään ’19.6.2023’.
Parent-Child -hierarkiat
Parent-Child-hierarkialla (Parent-Child hierarchy) voidaan kuvata hierarkkista dimensiota, jonka syvyys vaihtelee. Tällainen tyypillinen hierarkia on esimerkiksi organisaatiodimensio, jossa organisaation eri tasoilla voi olla vaihteleva määrä esihenkilöitä sekä alaisia. Viittaukseen käytetään tyypillisesti ns. ParentId -kenttää, joka viittaa dimensiotauluun itseensä (=implosion).
Hitaasti muuttuvat dimensiot (SCD, Slowly Changing Dimension)
Hitaasti muuttuvat dimensiot (=SCD) kuvaavat dimensiotiedon muutosta ajan funktiona. Tämä on tietovaraston merkittävä etu verrattuna operatiivisiin tietokantoihin, joissa on tyypillistä että niistä säilötään vain viimeisin tieto. Näitä ovat SCD0, SCD1, SCD2, SCD3, SCD4, SCD5, SCD6 sekä SCD7, joista yleisimpiä ovat SCD0, SCD1 ja SCD2. Kaikki nämä tietueet identifioidaan luonnollisen avaimen perusteella. Tyypillisimmät SCD:t ovat:
– SCD0-dimensiossa säilytetään aina alkuperäinen arvo. Tällaista tietoa ovat mm. auton rekisterinumero sekä henkilön syntymäpäivä. Tämän SCD-tyypin heikkous on se, että dimensiohistoriaa ei synny.
– SCD1-tyyppisessä dimensiossa kenttäkohtaiset muutokset jyrätään aina yli ilman historiointia. Tämän SCD-tyypin heikkous on se, että vanhaa dimensiohistoriaa ei säilötä siihen linkitetyn faktan suhteen, vaan ainoastaan viimeinen arvo merkkaa.
– SCD2-tyyppisessä dimensiossa joko lisätään aina kokonaan uusi rivi tietueen muuttuessa höystettynä versioattribuutilla tai sitten lisätään start date- ja end date -kentät näyttämään mihin kukin tietue on voimassa (NULL end datena nykytilanteessa). Kolmas vaihtoehto on merkata kullekin tietueelle effective date ja current flag (N/Y). Tämän SCD-tyypin heikkous on lähinnä se, että mikäli dimension muutostiheys on suuri ja attribuutteja on paljon, dataa voi kertyä todella runsaasti – tämä voi olla joskus haaste latausajoille sekä taulun indeksoinnin suhteen.
Monsteridimensiot
Monstereita ovat sellaiset dimensiot, joissa tietuemäärä kasvaa niin suureksi, että se alkaa vaikuttamaan tietovarastokannan suorituskykyyn. Näitä dimensioita kannattaa usein pilkkoa pienemmiksi, luokitteleviksi dimensioiksi, jotta suorituskyky paranee. Samalla säästetään tilaa. Tähän on olemassa lukuisia eri tekniikoita sekä parhaita käytäntöjä. Eräs tekniikka on luoda ns. identity-profile-dimensiopareja, joista identity-dimensioon säilötään dimension muuttumattomat attribuutit ja profile-dimensioon dimension muuttuvat tiedot. Tämän seurauksena tietuemäärät vähenevät ja turhalta toisteisuudelta vältytään. Tietovarastossakin rajulla denormalisoinnilla on hintansa.
Yhteenveto
Tähtimalli voi kuulostaa simppeliltä ja pitkälle sitä onkin, mutta isommissa ja kompleksisemmissa ympäristöissä huono mallintamistekniikka johtaa helposti kömpelöön tietomalliin, jota on hankala ylläpitää ja jonka suorituskyky ja tilantarpeet ovat haastavat ja raportoitavuus sekä tuki kehittyneelle analytiikalle ovat puutteelliset. Tämän takia tähtimallista sekä siihen liittyvästä ns. dimensiomallintamisesta on jokaisen päteväksi tietomallintajaksi tähyävän syytä tuntea enemmänkin kuin vain perusteet. Tässä blogipostauksessani kävin läpi pääsääntöisesti vain perusteita. Erinomaista syväluotausta tähtimalliin liittyen löydät mm. Ralph Kimballin kirjasta ”The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling”.
Onko organisaatiossanne tietovarastointitarpeita? Otathan yhteyttä niin keskustellaan lisää!

Jani K. Savolainen
jani.savolainen@dbproservices.fi
0440353637
VP & Chairman
DB Pro Services Oy