

Tämä postaus aloittaa blogisarjan tietomallinnuksesta. Alla linkit muihin tietomallinnuksen blogisarjan blogeihin.
- Tietomallinnus – Osa 2: Kolmas normaalimuoto (OLTP)
- Tietomallinnus – Osa 3: Tähtimalli (Star schema)
- Tietomallinnus – Osa 4: Lumihiutalemalli (Snowflake schema)
- Tietomallinnus – Osa 5: Enterprise Data Warehouse BUS
- Tietomallinnus – Osa 6: Data Vault
Tietomallinnuksen hyödyt
Tietomallinnus on keskeinen vaihe tietokantojen suunnitteluprosessissa, ja sillä on useita hyötyjä. Tietomallinnuksen avulla voidaan varmistaa, että tietokanta on tehokas, joustava ja laajennettavissa tulevaisuuden tarpeisiin. Tässä on joitakin tärkeimpiä hyötyjä, joita tietomallinnuksesta on tietokantojen suunnittelussa:
1. Ymmärryksen parantaminen: Tietomallinnus auttaa suunnittelijoita ja sidosryhmiä ymmärtämään liiketoiminnan prosesseja ja tiedonkäsittelyn vaatimuksia syvällisemmin. Se tarjoaa visuaalisen esityksen tiedon rakenteesta, suhteista ja rajoitteista, mikä helpottaa yhteistä ymmärrystä ja kommunikointia.
2. Tehokkuuden lisääminen: Hyvin suunniteltu tietomalli mahdollistaa tietokannan tehokkaamman käytön, koska se minimoi tarpeettoman datan toistumisen ja optimoi tiedon tallennuksen ja haun.
3. Joustavuus ja laajennettavuus: Kun tietokanta on suunniteltu huolellisesti tietomallinnuksen avulla, sen rakenne on joustavampi ja helpommin mukautettavissa muuttuviin liiketoiminnan tarpeisiin ja teknologisiin vaatimuksiin.
4. Laadun parantaminen: Tietomallinnus auttaa tunnistamaan ja korjaamaan suunnitteluvirheitä varhaisessa vaiheessa, mikä vähentää virheitä ja parantaa tietokannan laatua ja suorituskykyä.
5. Tietoturvan ja yksityisyyden varmistaminen: Tietomallinnuksen avulla voidaan suunnitella tietokannan turvatoimet ja yksityisyydensuoja alusta alkaen, mikä varmistaa arkaluonteisen tiedon asianmukaisen käsittelyn ja suojauksen.
6. Kustannusten vähentäminen: Vaikka tietomallinnus vaatii alkuinvestointia, aikaa ja resursseja, se voi säästää merkittävästi kustannuksia pitkällä aikavälillä vähentämällä tarvetta tietokannan jälkikäteisille muutoksille ja korjauksille.
7. Standardisoinnin edistäminen: Tietomallinnus auttaa noudattamaan alan standardeja ja parhaita käytäntöjä, mikä helpottaa integraatiota muiden järjestelmien kanssa ja edistää tiedon yhteentoimivuutta.
Tietomallinnus on siis olennainen osa tietokantojen suunnittelua, joka auttaa rakentamaan tehokkaita, luotettavia ja tulevaisuuden tarpeisiin mukautuvia tietokantoja.
Miksi ja milloin tietomallinnus tehdään
Tietomallinnus, eli tietomallintaminen on tärkein yksittäinen vaihe reaaliaikaisen (OLTP) tietojärjestelmän tai tietovaraston (DW, Datamart) toteutuksessa. Tämän tehtävän suorittaa tyypillisesti asiaan vihkiytynyt tietomallintaja. Tietomallinnus kuvataan usein kaksivaiheisena prosessina: Sen ensisijaisena tarkoituksena on luoda ylätasolla yhteinen käsitekartta liiketoiminnan, tietokantaosaajien (data-arkkitehti, DBA), datainsinöörien (Data Engineer) sekä data-analyytikoiden (Data Analyst) välille. Tällöin puhutaan käsiteanalyysistä. Kun käsiteanalyysi on valmis, valitaan skenaarioon parhaiten sopiva tietomallinnusmetodi ja suunnitellaan ns. fyysinen tietomalli. Fyysisen tietomallin pohjalta voidaan sitten toteuttaa varsinainen tietokanta. Fyysisiä tietomalleja ovat mm.
- OLTP- eli relaatiomalli (3NF)
- Star Schema (tähtimalli)
- Snowflake Schema (lumihiutalemalli)
- Enterprise Data Warehouse BUS
- Data Vault
Fyysisen tietomallin tehtävänä on palvella liiketoiminnan tarpeita mahdollisimman tehokkaasti. Hyvä fyysinen tietomalli ottaa liiketoimintatarpeiden lisäksi huomioon mm. seuraavat seikat:
- Tietokantaratkaisun suorituskyky sekä skaalautuvuus käyttöskenaarion mukaan
- Tietomallin ymmärrettävyys
- Tietomallin ylläpidettävyys sekä:
- Tietomallin helppokäyttöisyys tietokantakyselyiden laatimisessa
Usein tietomallinnuksessa tehdään sellainen virhe, että käsiteanalyysin sijaan lähdetään kuvaamaan suoraan tietokannan fyysistä tietomallia, joka johtaa mm. siihen, että DBA tuo turhaan monimutkaisia teknisiä yksityiskohtia liiketoiminnan pohdittavaksi. Lisäksi tuollaisessa lähestymistavassa on merkittävä vaara, että liiketoiminta tulee tähän fyysiseen tietomalliin väärinkuvatuksi ja sitä kautta fyysisen datamallin refaktorointikustannukset voivat olla dramaattiset, etenkin jos ollaan jo tuotannossa. Vaikka jotkin fyysiset tietomallit kuten Data Vault 2.0 ja suoraviivaisesti toteutettu Star schema (full load), antavatkin paremmin anteeksi mahdollisia ”suunnittelukukkasia”. Tämän takia tietomallintamiseen kannattaa suhtautuakin iteratiivisena prosessina, jossa tietomallia hiotaan asteittain, kunnes lopputulos vastaa tarkasti liiketoimintaa. Lisäksi on hyvä tiedostaa, että hyväkään fyysinen tietomalli ei millään tavoin korvaa kyvykkään DBA:n osuutta tietokannan suorituskyvyllisten ominaisuuksien maksimoimisessa, vaan ainoastaan antaa siihen ainoastaan parhaan mahdollisen pohjan. Jos verrattaisiin datahanketta talonrakentamiseen, voitaisiinkin ajatella, että tietomallintaminen on eräänlaista arkkitehtityötä ja tietokannan fyysinen koodaaminen insinöörityötä.
Tietomallinnuksen ylätason käsiteanalyysi
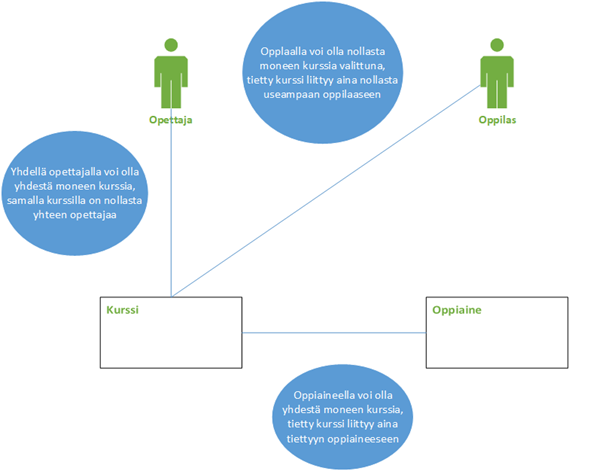
Tietomallinnuksessa olennaisia ovat oliot, olioiden ominaisuudet sekä olioiden väliset suhteet eli relaatiot. Reaalimaailmassa voidaan kuvata miltei mikä tahansa kokonaisuus mielekkäästi ja ymmärrettävästi nk. käsitemallin avulla. Reaalimaailmassa olioita ovat ne asiat, joilla voi olla useita ominaisuuksia eli attribuutteja. Yksittäinen olio voi sitten joko liittyä tai olla liittymättä toisiin olioihin. Tätä suhdetta olioiden välillä kutsutaan relaatioksi.
Ohessa yksinkertaistettu esimerkki koulumaailmasta, jossa mallinnetaan lukion oppilastietojärjestelmää:
Olioita ovat:
- Opettaja
- Oppilas
- Oppiaine
- Kurssi
Ominaisuudet jakautuvat olioittain:
Opettajan ominaisuuksia ovat esimerkiksi:
- Etunimi
- Sukunimi
- Syntymäaika
- Opettajanumero (numero, joka identifioi oppilaan tietojärjestelmässä)
Oppilaan ominaisuuksia ovat esimerkiksi:
- Etunimi
- Sukunimi
- Syntymäaika
- Oppilasnumero (numero, joka identifioi oppilaan tietojärjestelmässä)
Oppiaineen ominaisuuksia ovat esimerkiksi.
- Nimi (Englanti, Matematiikka, Psykologia jne.)
- Kategoria (Kielet, Luonnontieteet, Kasvatustieteet jne.)
Kurssin ominaisuuksia ovat esimerkiksi:
- Nimi (Englannin preppauskurssi abeille, Tilastotieteen perusteet, Johdanto psykologiaan)
- Kesto (Kurssin kesto opintoviikkoina)
- Alkupvm (Esim. 1.4.2023)
- Loppupvm (Esim. 30.5. 2023)
Relaatio siis kuvaa olioiden välistä suhdetta. Relaatioita voi olla erilaisia. Niitä kuvataan käsitteillä ”nolla”, ”yksi” tai ”monta”. Esimerkiksi:
- Opettajalla voi olla ”yhdestä moneen” kurssia opetettavanaan
- Kurssi voi liittyä vain ”yhteen” (=tiettyyn) oppiaineeseen
- Oppilaalla voi olla ”nollasta moneen” kurssia valittuna (kun oppilas aloittaa kurssien valitsemisen niitä ei ole yhtään valittuna)
Tästä voidaan edelleen olemassa olevien sääntöjen varassa päätellä että:
- Opettajalla voi olla ”yhdestä moneen” oppiainetta (joku oppiaine on oltava ja jotkut opettaja hallitsevat useammankin oppiaineen)
- Opettajalla voi olla ”nollasta moneen” oppilasta tietyssä kurssissa (joskus oppilaat eivät valitse tiettyä kurssia ollenkaan)
- Oppilaalla voi olla ”yhdestä moneen” oppiainetta valittuna (pakko olla ainakin yksi oppiaine)
Käsiteanalyysissä muodostuvaa tietomallia voidaan ylätasolla kuvata yksinkertaisimmillaan näin:
Nyt kun ylätason käsitemalli on selkeä, introan fyysisiä tietomalleja.
Fyysinen tietomalli – OLTP- eli relaatiomalli (3NF)
Operatiiviset eli ns. OLTP-tietokannat ovat transaktiointensiivisiä. Tämä tarkoittaa, että dataa kirjoitetaan ja päivitetään tietokannassa tiuhaan tahtiin lukuoperaatioiden lisäksi. Tällaisia ovat mm. ERP-järjestelmien tietokannat. OLTP-työkuormille tyypillisiä piirteitä ovat pienet tulosjoukot sekä yksinkertaiset kyselyt. Hyvä OLTP-tietomalli on sellainen, jossa oliot ja niiden ominaisuudet esitetään hyvin normalisoituna, kerran ja vain kerran, relaatioineen. Täten saadaan tietokannan transaktionaalinen suorituskyky maksimoitua ja mahdolliset lukitustilanteet minimoitua. Lue täältä lisää OLTP tietokantojen mallinnusmenetelmästä.
Fyysinen tietomalli – Star Schema (tähtimalli)
Eräs fyysisten tietomallien tyypeistä on ns. tähtimalli. Se on raportointitietokannoissa (data mart, EDW) yleisimmin käytetty tietomalli. Tähtimalli on myös OLAP-teknologiassa käytetty skeema ja sitä käytetään hyvin yleisesti myös Power BI-raportoinnissa. Tähtimallin skeema sijoitetaan lähes poikkeuksetta omaan tietokantaansa sen intensiivisten lataus- / tietokantakyselykuormien takia, jotka poikkeavat merkittävästi perinteisten OLTP-kantojen työkuormatyypeistä. Tähtimallissa esitetään laskennallinen data ns. faktatauluissa, joita ympäröivät laskennallista tietoa tyypittävät dimensiotaulut. Lue täältä lisää Star Schema (tähtimalli) tietokantojen mallinnusmenetelmästä.
Fyysinen tietomalli – Snowflake Schema (lumihiutalemalli)
Lumihiutalemalli on eräs fyysisen tietomallintamisen menetelmä, jolla voidaan rakentaa tietovarastoja ja data martteja. Se on läheistä sukua tähtimallille ja hieman etäisemmin data vaultille. Lumihiutalemallissa on enemmän tauluja sekä niiden välisiä liitoksia kuin tähtimallissa, toisin sanoen malli on normalisoidumpi kuin tähtimallissa mutta denormalisoidumpi kuin OLTP-mallissa: Siinä missä tähtimallissa kunkin faktataulun ympärille generoituu yksiulotteisia ”tähden sakaroita” eli dimensioita, lumihiutalemallissa normalisoidaan dimensiorakennetta niveltämällä tähtien sakaroihin ns. ”alidimensioita”. Lue täältä lisää Snowflake Schema (lumihiutalemalli) tietokantojen mallinnusmenetelmästä.
Fyysinen tietomalli – Enterprise Data Warehouse BUS
Enterprise Data Warehouse BUS on eräs fyysisen tietomallinnuksen menetelmä, tai enemmänkin arkkitehtuurinen tapa ajatella tietomallinnusta, jolla voidaan rakentaa konsernitietovarastoja tähtimallin päälle siten, että se ottaa huomioon bisneksen ns. 360-näkymän. Tämä tarkoittaa käytännössä eri järjestelmien välistä yhteistä master dataa, jotka mallinnetaan dimensioiksi. Lue täältä lisää Enterprise Data Warehouse BUS tietokantojen mallinnusmenetelmästä.
Fyysinen tietomalli – Data Vault
Data Vault on tietomallinnuksen ja tietovarastoinnin menetelmä, joka soveltuu monimutkaisen ja muuttuvan tiedon liiketoimintaympäristöön. Tällaisissa liiketoimintaympäristöissä dataa luetaan tietovarastoon useista eri lähteistä suurilla volyymeilla. Data Vault -menetelmän ajatuksena on rakentaa yksilöllisesti linkitetty joukko normalisoituja tietokantatauluja ja mahdollistaa näin tarkka tiedontaso. Data Vault -menetelmässä yhdistetään kolmannen normaalinmuodon (OLTP) ja dimensionallisen tietomallintamisen parhaat puolet yhdeksi hybridimalliksi. Lue täältä lisää Data Vault tietokantojen mallinnusmenetelmästä.
Kiinnostuitko aiheesta? Onko organisaatiossasi ehkä käynnistymässä tietojärjestelmähanke, johon tarvitset tietomallintamisen ammattilaisen apua? Ole hyvä ja ota meihin yhteyttä, ehkä voimme olla avuksi!
Jani K. Savolainen
VP & Chairman
DB Pro Services Oy
Sinua saattaa kiinnostaa myös:
SQL-tietokanta – historia, nykytila ja tulevaisuus: nykytila
Power BI pro ja eri lisensiointimallit
Tiedonhallinta: Kuinka hyödyntää organisaation dataa laajasti, mutta hallitusti
Mikä on Lakehouse tietoalustaratkaisu ja kuinka organisoida data tehokkaasti Lakehousessa?



